标签搜索


搜索到
27
篇与
的结果
-
 Redis及其基本操作 目标1、能够知道redis的5种数据结构;string list hash set zset2、能够运用set、get、del、keys命令;3、能够运用hset、hget、hmset、hmget、hgetall、hdel命令;4、能够运用lpush、lpop、rpush、rpop命令;5、能够运用sadd、zadd命令;一、Redis概述1.1、简介Redis是Remote Dictionary Server(远程词典服务)的缩写,Redis 是完全开源免费的,遵守BSD协议的NOSQL数据库,Redis使用C语言编写,它的数据模型为 key-value。Redis是一个单进程单线程,非阻塞I/ORedis 与其他 key - value 缓存产品有以下三个特点:Ø Redis支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。Ø Redis不仅支持简单的key-value(string)类型的数据,同时还提供list[列表],set[集合],zset[有序集合],hash[hash]等数据结构的存储。Ø Redis支持服务器主从模式[集群-高可用]。redis和memcache区别² redis支持数据的持久化,而memcache不支持² redis不但有string类型的key-value还有更多的数据结构存储,而memcache则只有string类型的key和value² memcache的集群很弱,而redis支持主从集群的² 端口不同 memcache 11211 redis 63791.2、Redis优势Ø 性能极高 – Redis能读的速度是110000次/s,写的速度是81000次/s 。Ø 丰富的数据类型 – Redis支持String, List, Hash, Set 及 Zset 数据类型操作。Ø 原子性 – Redis的所有操作都是原子性的,意思就是要么成功执行要么失败完全不执行。多个操作也支持事务,通过MULTI和EXEC指令包起来。Ø api支持的语言丰富,调用简单(面向对象)。二、 数据结构类型操作redis提供5种 string 字符串 list 列表 set 集合 zset 有序集合 hash3.1、Redis对key的操作命令【redis服务器相关】查找所有符合给定模式的keykeys 查询相应的key或通配符(*)图片工具添加2个keykeys查看用于检查给定 key 是否存在 返回0/1 0不存在,1存在exists key查看当前数据库中设置key的数量dbsize清除当前数据库中的数据flushdb切换数据库select N清除所有数据库中的数据flushall注:flushdb 还是flushall 两个尽量不要用,知道就行,在开发时,可以用一用,上线一定不要用。3.2、字符串(string)操作命令用于设置给定 key 的值。如果 key 已经存储其他值, SET 就覆写旧值,且无视类型set key value [ex 秒数]/[px 毫秒数] [nx]/[xx]注后两个参数一般不写ex/px 缓存有效期 exnx: 表示key不存在时,执行操作xx: 表示key存在时,执行操作 默认设置带过期时间的key查看value类型存在则添加失败,不存在则添加成功 nx存在则修改,不存在则添加 xx设置key有效期用于获取指定 key 的值。如果 key 不存在,返回 nil 。如果key 储存的值不是字符串类型,返回一个错误get key一次性设置多个键值mset key1 value1 key2 value2 …获取多个key的值mget key1 key2 key3 …自增与自减 直接用,key自动创建,不需要先setincr key # 自增 每次自增1 decr key # 自减 每次自减1 incrby key step # 指定步长的自增 可为负数 decrby key step # 指定步长的自减把value追加到key的原值上append key value设置新值同步返回旧值getset key newValue3.3、列表(list)操作命令类似于PHP中的索引数组,列表中的值是可以重复的。可以用列表来实现简单的队列。可以实现先进后出,还可以实现先进先出把值插入到列表的头部(左边)lpush key value从列表右边(尾部)删除元素,并返回删除的元素值rpop key注:使用lpush 和 rpop 实现了 先进先出。获取列表的长度llen key返回指定区间内的元素,下标从0开始lrange key startIndex endIndex注: 默认从左开始向右获取指定索引的值,从右开始负数开始,-1就是右边第1个元素。从左边开始从右边开始从尾部添加rpush key value从头部删除元素并返回删除元素值lpop key移除列表的最后一个元素,并将该元素添加到另一个列表并返回rpoplpush mylist otherlist3.4、哈希(hash)操作命令类似于PHP的关联数组。一般用于存储数据表中一条记录值。关于hash的key的起名称:一般和数据表关联表名:主键字段名:id值 user:id:1 hash的key值把key中 field字段的值设置为 value,如果没有field字段,直接添加,如果有,则覆盖原field字段的值hset key field value一次性设置多个hmset key field1 value1 field2 value2 …获取key中指定field字段的值hget key field一次性获取之个key中field字段的值hmget key field1 field2 …返回key中所有字段的值hgetall key把数据库中用户表中id为1的用户信息存到redis中给hash中的key值单个设置值和单个key中的字段来获取。批量获取和添加删除key中指定的field字段hdel key field返回key中元素的数量hlen key判断key中有没有field字段hexists key field把key中field字段的值自增长hincrby key field step 步长可以为负数返回所有key对应的field字段hkeys key返回所有key对应field字段对应的值hvals key3.5、集合(set)操作命令redis的set是无序集合。集合里不允许有重复的元素。set元素最大可以包含(2的32次方-1)个元素。场景:存放用户Id,不重复的信息 抽奖,好友关系向集合key中添加元素sadd key value1 value2返回key集合中所有的元素smembers key返回key集合中元素的个数scard key删除key集合中为value1的元素srem key value1随机删除key集合中的1个元素并返回spop key判断value是否存在于key集合中sismember key value把源集合中的value删除,并添加到目标集合中 【移动】smvoe sSet dSet value求出key1,key2两个集合的交集,并返回sinter key1 key2求出key1,key2两个集合的并集,并去重,并返回sunion key1 key2求出key1与key2的差集sdiff key1 key2 以key1集合为主,求出key1中和key2不同的元素并返回3.6、有序集合(zset)操作命令和set一样有序集合,元素不允许重复,不同的是每个元素都会关联一个分值。可以通过它的分值来进行排序。如实现手机APP市场的软件排名等需求的实现。给key有序集合中添加元素zadd key score(分值) value删除key有序集合中指定的元素zrem key value1返回有序集中,指定区间位置内的成员zrange key startIndex endIndex [withscores] # 从小到大排列 zrevrange key startIndex endIndex [withscores] # 从大到小排列按照分值来删除元素,删除score在 min<=score<=max之间的zremrangebyscore key min max返回集合元素个数zcard key返回min <= score <= max分值区间内元素的数量zcount key minScore maxScore返回有序集中,成员的分数值zscore key value对有序集合中指定成员的分数加上增量 把value的分数+score值zincrby key score 元素字符串set key value [ex/px nx/xx] get key mset key value key value mget key1 key2 key3 ttl key expire key time incrby key step append key value getset key newValue del key列表 listlpush rpop rpush lpop rpoplpush llen lrange key start endhashhset hmset hget key fileld hmget key f1 f2 f3 hgetall key hlen hexists hdel hincrby无序集合 setsadd smembers scards sismember smove sset dset value srem spop sinter 交集 sunion 并集 sdiff set1 set2 差集有序集合 zsetzadd key score value zrange key start end zrevrange zrem zcard zincrby 分值添加 zremrangebyscore 分值区间来删除 zcount 分值区间总数 zscore 元素分值
Redis及其基本操作 目标1、能够知道redis的5种数据结构;string list hash set zset2、能够运用set、get、del、keys命令;3、能够运用hset、hget、hmset、hmget、hgetall、hdel命令;4、能够运用lpush、lpop、rpush、rpop命令;5、能够运用sadd、zadd命令;一、Redis概述1.1、简介Redis是Remote Dictionary Server(远程词典服务)的缩写,Redis 是完全开源免费的,遵守BSD协议的NOSQL数据库,Redis使用C语言编写,它的数据模型为 key-value。Redis是一个单进程单线程,非阻塞I/ORedis 与其他 key - value 缓存产品有以下三个特点:Ø Redis支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。Ø Redis不仅支持简单的key-value(string)类型的数据,同时还提供list[列表],set[集合],zset[有序集合],hash[hash]等数据结构的存储。Ø Redis支持服务器主从模式[集群-高可用]。redis和memcache区别² redis支持数据的持久化,而memcache不支持² redis不但有string类型的key-value还有更多的数据结构存储,而memcache则只有string类型的key和value² memcache的集群很弱,而redis支持主从集群的² 端口不同 memcache 11211 redis 63791.2、Redis优势Ø 性能极高 – Redis能读的速度是110000次/s,写的速度是81000次/s 。Ø 丰富的数据类型 – Redis支持String, List, Hash, Set 及 Zset 数据类型操作。Ø 原子性 – Redis的所有操作都是原子性的,意思就是要么成功执行要么失败完全不执行。多个操作也支持事务,通过MULTI和EXEC指令包起来。Ø api支持的语言丰富,调用简单(面向对象)。二、 数据结构类型操作redis提供5种 string 字符串 list 列表 set 集合 zset 有序集合 hash3.1、Redis对key的操作命令【redis服务器相关】查找所有符合给定模式的keykeys 查询相应的key或通配符(*)图片工具添加2个keykeys查看用于检查给定 key 是否存在 返回0/1 0不存在,1存在exists key查看当前数据库中设置key的数量dbsize清除当前数据库中的数据flushdb切换数据库select N清除所有数据库中的数据flushall注:flushdb 还是flushall 两个尽量不要用,知道就行,在开发时,可以用一用,上线一定不要用。3.2、字符串(string)操作命令用于设置给定 key 的值。如果 key 已经存储其他值, SET 就覆写旧值,且无视类型set key value [ex 秒数]/[px 毫秒数] [nx]/[xx]注后两个参数一般不写ex/px 缓存有效期 exnx: 表示key不存在时,执行操作xx: 表示key存在时,执行操作 默认设置带过期时间的key查看value类型存在则添加失败,不存在则添加成功 nx存在则修改,不存在则添加 xx设置key有效期用于获取指定 key 的值。如果 key 不存在,返回 nil 。如果key 储存的值不是字符串类型,返回一个错误get key一次性设置多个键值mset key1 value1 key2 value2 …获取多个key的值mget key1 key2 key3 …自增与自减 直接用,key自动创建,不需要先setincr key # 自增 每次自增1 decr key # 自减 每次自减1 incrby key step # 指定步长的自增 可为负数 decrby key step # 指定步长的自减把value追加到key的原值上append key value设置新值同步返回旧值getset key newValue3.3、列表(list)操作命令类似于PHP中的索引数组,列表中的值是可以重复的。可以用列表来实现简单的队列。可以实现先进后出,还可以实现先进先出把值插入到列表的头部(左边)lpush key value从列表右边(尾部)删除元素,并返回删除的元素值rpop key注:使用lpush 和 rpop 实现了 先进先出。获取列表的长度llen key返回指定区间内的元素,下标从0开始lrange key startIndex endIndex注: 默认从左开始向右获取指定索引的值,从右开始负数开始,-1就是右边第1个元素。从左边开始从右边开始从尾部添加rpush key value从头部删除元素并返回删除元素值lpop key移除列表的最后一个元素,并将该元素添加到另一个列表并返回rpoplpush mylist otherlist3.4、哈希(hash)操作命令类似于PHP的关联数组。一般用于存储数据表中一条记录值。关于hash的key的起名称:一般和数据表关联表名:主键字段名:id值 user:id:1 hash的key值把key中 field字段的值设置为 value,如果没有field字段,直接添加,如果有,则覆盖原field字段的值hset key field value一次性设置多个hmset key field1 value1 field2 value2 …获取key中指定field字段的值hget key field一次性获取之个key中field字段的值hmget key field1 field2 …返回key中所有字段的值hgetall key把数据库中用户表中id为1的用户信息存到redis中给hash中的key值单个设置值和单个key中的字段来获取。批量获取和添加删除key中指定的field字段hdel key field返回key中元素的数量hlen key判断key中有没有field字段hexists key field把key中field字段的值自增长hincrby key field step 步长可以为负数返回所有key对应的field字段hkeys key返回所有key对应field字段对应的值hvals key3.5、集合(set)操作命令redis的set是无序集合。集合里不允许有重复的元素。set元素最大可以包含(2的32次方-1)个元素。场景:存放用户Id,不重复的信息 抽奖,好友关系向集合key中添加元素sadd key value1 value2返回key集合中所有的元素smembers key返回key集合中元素的个数scard key删除key集合中为value1的元素srem key value1随机删除key集合中的1个元素并返回spop key判断value是否存在于key集合中sismember key value把源集合中的value删除,并添加到目标集合中 【移动】smvoe sSet dSet value求出key1,key2两个集合的交集,并返回sinter key1 key2求出key1,key2两个集合的并集,并去重,并返回sunion key1 key2求出key1与key2的差集sdiff key1 key2 以key1集合为主,求出key1中和key2不同的元素并返回3.6、有序集合(zset)操作命令和set一样有序集合,元素不允许重复,不同的是每个元素都会关联一个分值。可以通过它的分值来进行排序。如实现手机APP市场的软件排名等需求的实现。给key有序集合中添加元素zadd key score(分值) value删除key有序集合中指定的元素zrem key value1返回有序集中,指定区间位置内的成员zrange key startIndex endIndex [withscores] # 从小到大排列 zrevrange key startIndex endIndex [withscores] # 从大到小排列按照分值来删除元素,删除score在 min<=score<=max之间的zremrangebyscore key min max返回集合元素个数zcard key返回min <= score <= max分值区间内元素的数量zcount key minScore maxScore返回有序集中,成员的分数值zscore key value对有序集合中指定成员的分数加上增量 把value的分数+score值zincrby key score 元素字符串set key value [ex/px nx/xx] get key mset key value key value mget key1 key2 key3 ttl key expire key time incrby key step append key value getset key newValue del key列表 listlpush rpop rpush lpop rpoplpush llen lrange key start endhashhset hmset hget key fileld hmget key f1 f2 f3 hgetall key hlen hexists hdel hincrby无序集合 setsadd smembers scards sismember smove sset dset value srem spop sinter 交集 sunion 并集 sdiff set1 set2 差集有序集合 zsetzadd key score value zrange key start end zrevrange zrem zcard zincrby 分值添加 zremrangebyscore 分值区间来删除 zcount 分值区间总数 zscore 元素分值 -
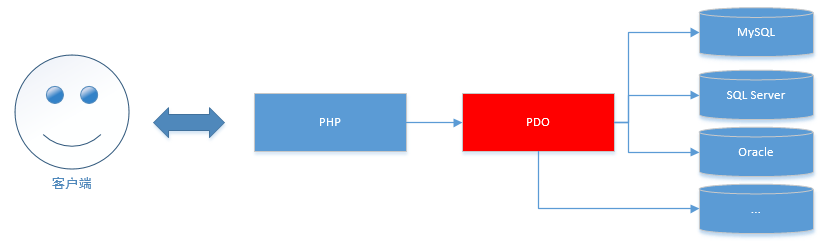
PDO-预处理、事务、异常处理、二次封装 1.1 目标理解PDO产生的价值;了解PDO中三个类各自主要的功能;掌握PDO类的对象实例化;了解PDO设置属性的原理;了解PDOStatement类对象产生的原理;掌握fetch数据获取的应用;掌握PDO中预处理的应用;了解PDO中事务处理的应用;了解PDO中的三种错误处理模式;掌握PDO异常的使用;理解PDO二次封装的意义;掌握PDO的二次封装;1.2 PDO介绍1.2.1 连接数据库方式方法一:mysql扩展【这种方式php7已经淘汰】方法二:mysqli扩展方法三:PDO扩展1.2.2 PDO介绍PDO(PHP Data Object)扩展为PHP访问各种数据库提供了一个轻量级,一致性的接口。无论访问什么数据库,都可以通过一致性的接口去操作。1.2.3 开启PDO扩展开启PDO连接MySQL扩展extension=php_pdo_mysql.dll1.3 PDO核心类1、PDO类:表示PHP和数据库之间的一个连接2、PDOStatement 类 第一:表示执行数据查询语句(select ,show)后的相关结果集 第二:预处理对象3、PDOException类:表示PDO的异常1.4 实例化PDO对象语法__construct($dsn,用户名,密码)1.4.1 DSNDSN:data source name,数据源名称,包含的是连接数据库的信息,格式如下:$dsn=数据库类型:host=主机地址;port=端口号;dbname=数据库名称;charset=字符集数据库类型:MySQL数据库 => mysql: oracle数据库 => oci: SQL Server =>sqlsrv: 具体驱动类型参见手册“PDO驱动”1.4.2 实例化PDO实例化PDO的过程就是连接数据库的过程<?php $dsn='mysql:host=localhost;port=3306;dbname=data;charset=utf8'; $pdo=new PDO($dsn,'root','root'); var_dump($pdo); //object(PDO)#1 (0) { } 1.4.3 注意事项1、如果连接的是本地数据库,host可以省略<?php $dsn='mysql:port=3306;dbname=data;charset=utf8'; $pdo=new PDO($dsn,'root','root'); var_dump($pdo); //object(PDO)#1 (0) { } 2、如果使用的是3306端口,port可以省略<?php $dsn='mysql:dbname=data;charset=utf8'; $pdo=new PDO($dsn,'root','root'); var_dump($pdo); //object(PDO)#1 (0) { } 3、charset也省略,如果省略,使用的是默认字符编码<?php $dsn='mysql:dbname=data'; $pdo=new PDO($dsn,'root','root'); var_dump($pdo); 4、dbname也可以省略,如果省略就没有选择数据库<?php $dsn='mysql:'; $pdo=new PDO($dsn,'root','root'); var_dump($pdo); 5、host、port、dbname、charset不区分大小写,没有先后顺序6、驱动名称不能省略,冒号不能省略(因为冒号是驱动名组成部分),数据库驱动只能小写1.5 使用PDO1.5.1 执行数据操作语句方法:$pdo->exec($sql),执行数据增、删、改语句,执行成功返回受影响的记录数,如果SQL语句错误返回false。<?php //1、实例化PDO $dsn='mysql:host=localhost;port=3306;dbname=data;charset=utf8'; $pdo=new PDO($dsn,'root','root'); //2执行数据操作语句 //2.1 执行增加 /* if($pdo->exec("insert into news values (null,'bb','bbbbbb',unix_timestamp())")) echo '自动增长的编号是:'.$pdo->lastInsertId (),'<br>'; */ //2.2 执行修改 //echo $pdo->exec("update news set title='静夜思' where id in (3,4)"); //2.3 执行删除 //echo $pdo->exec('delete from news where id=5');\ //2.4 完善 $sql="update news set title='静夜思1' where ids in (3,4)"; $rs=$pdo->exec($sql); if($rs){ echo 'SQL语句执行成功<br>'; if(substr($sql, 0,6)=='insert') echo '自动增长的编号是:'.$pdo->lastInsertId (),'<br>'; else echo '受到影响的记录数是:'.$rs,'<br>'; }elseif($rs===0){ echo '数据没有变化<br>'; }elseif($rs===false){ echo 'SQL语句执行失败<br>'; echo '错误编号:'.$pdo->errorCode(),'<br>'; //var_dump($pdo->errorInfo()); echo '错误信息:'.$pdo->errorInfo()[2]; }1.5.2 执行数据查询语句方法:$pdo->query($sql),返回的是PDOStatement对象<?php $dsn='mysql:dbname=data;charset=utf8'; $pdo=new PDO($dsn,'root','root'); //1、执行数据查询语句 $stmt=$pdo->query('select * from products'); //var_dump($stmt); //object(PDOStatement) //2、获取数据 //2.1 获取二维数组 //$rs=$stmt->fetchAll(); //默认返回关联和索引数组 //$rs=$stmt->fetchAll(PDO::FETCH_BOTH); //返回关联和索引数组 //$rs=$stmt->fetchAll(PDO::FETCH_NUM); //返回索引数组 //$rs=$stmt->fetchAll(PDO::FETCH_ASSOC); //返回关联数组 //$rs=$stmt->fetchAll(PDO::FETCH_OBJ); //返回对象数组 //2.2 获取一维数组,匹配完成后指针下移一条 //$rs=$stmt->fetch(); //关联和索引数组 //$rs=$stmt->fetch(PDO::FETCH_NUM); //索引数组 //例题:通过while循环获取所有数据 /* while($row=$stmt->fetch(PDO::FETCH_ASSOC)){ $rs[]=$row; } echo '<pre>'; var_dump($rs); */ //3.3 匹配列:匹配当前行的第n列,列的编号从0开始,匹配完毕后指针下移一条 //echo $stmt->fetchColumn(); //获取当前行的第0列 //echo $stmt->fetchColumn(1); //获取当前行的第1列 //3.4 总行数,总列数 /* echo '总行数:'.$stmt->rowCount(),'<br>'; echo '总列数:'.$stmt->columnCount(); */ //3.5 遍历PDOStatement对象(PDOStatement对象是有迭代器的) foreach($stmt as $row){ echo $row['proname'],'-',$row['proprice'],'<br>'; }stdClass类是所有PHP类的父类1.5.3 PDO操作事务事务:是一个整体,要么一起执行,要么一起回滚事务的特性:原子性,一致性,隔离性,永久性需要将多个SQL语句作为一个整体执行,就需要使用到事务语法start transaction 或 begin 开启事务 commit 提交事务 rollback 回滚事务例题创建测试数据create table bank( cardid char(4) primary key comment '卡号', balance decimal(10,2) not null comment '余额' )engine=innodb charset=utf8 comment '银行卡号表' insert into bank values ('1001',1000),('1002',1)PDO操作事务<body> <?php if(!empty($_POST)){ $dsn='mysql:dbname=data;charset=utf8'; $pdo=new PDO($dsn,'root','root'); $out=$_POST['card_out']; //转出卡号 $in=$_POST['card_in']; //注入卡号 $money=$_POST['money']; //金额 $pdo->beginTransaction(); //开启事务 //转账 $flag1=$pdo->exec("update bank set balance=balance-$money where cardid='$out'"); $flag2=$pdo->exec("update bank set balance=balance+$money where cardid='$in'"); //查看转出的账号是否大于0,大于0返回true,否则返回false $stmt=$pdo->query("select balance from bank where cardid='$out'"); $flag3=$stmt->fetchColumn()>=0?1:0; if($flag1 && $flag2 && $flag3){ $pdo->commit (); //提交事务 echo '转账成功'; } else{ $pdo->rollBack (); //回滚事务 echo '转账失败'; } } ?> <form action="" method="post"> 转出卡号: <input type="text" name="card_out" id=""> <br> 转入卡号: <input type="text" name="card_in" id=""> <br> 金额:<input type="text" name="money" id=""> <br> <input type="submit" value="提交"> </form> </body>运行结果小结: $pdo->beginTransaction() 开启事务 $pdo->commit () 提交事务 $pdo->rollBack() 回滚事务1.5.4 PDO操作预处理复习MySQL中预处理预处理好处:编译一次多次执行,用来解决一条SQL语句多次执行的问题,提高了执行效率。预处理语句:prepare 预处理名字 from 'sql语句'执行预处理execute 预处理名字 [using 变量]PDO中的预处理——位置占位符<?php $dsn='mysql:dbname=data;charset=utf8'; $pdo=new PDO($dsn,'root','root'); //创建预处理对象 $stmt=$pdo->prepare("insert into bank values (?,?)"); //?是占位符 //执行预处理 $cards=[ ['1003',500], ['1004',100] ]; foreach($cards as $card){ //绑定参数,并执行预处理, //方法一: /* $stmt->bindParam(1, $card[0]); //占位符的位置从1开始 $stmt->bindParam(2, $card[1]); $stmt->execute(); //执行预处理 */ //方法二: /* $stmt->bindValue(1, $card[0]); $stmt->bindValue(2, $card[1]); $stmt->execute(); */ //方法三:如果占位符的顺序和数组的顺序一致,可以直接传递数组 $stmt->execute($card); }PDO中的预处理——参数占位符<?php $dsn='mysql:dbname=data;charset=utf8'; $pdo=new PDO($dsn,'root','root'); //创建预处理对象 $stmt=$pdo->prepare("insert into bank values (:p1,:p2)"); //:p1,:p2是参数占位符 //执行预处理 $cards=[ ['p1'=>'1003','p2'=>500], ['p1'=>'1004','p2'=>1000] ]; foreach($cards as $card){ //方法一: /* $stmt->bindParam(':p1', $card['p1']); $stmt->bindParam(':p2', $card['p2']); $stmt->execute(); */ //方法二:但数组的下标和参数名一致的时候就可以直接传递关联数组 $stmt->execute($card); }小结:1、?是位置占位符2、参数占位符以冒号开头3、$stmt->bindParam()和$stmt->bindValue()区别4、预处理的好处a)提高执行效率 b)提高安全性1.6 PDO异常处理<?php try{ $dsn='mysql:dbname=data;charset=utf8'; $pdo=new PDO($dsn,'root','root'); //这是PDO错误模式属性,PDO自动抛出异常 $pdo->setAttribute(PDO::ATTR_ERRMODE, PDO::ERRMODE_EXCEPTION); $pdo->query('select * from newsssssss'); //自动抛出异常 } catch (PDOException $ex) { echo '错误信息:'.$ex->getMessage(),'<br>'; echo '错误文件:'.$ex->getFile(),'<br>'; echo '错误行号:'.$ex->getLine(); }小结:1、PDOException是PDO的异常类2、实例化PDO会自动抛出异常3、其他操作不会抛出异常,需要设置PDO的异常模式4、PDO异常模式PDO::ERRMODE_EXCEPTION 抛出异常 PDO::ERRMODE_SILENT 中断 PDO::ERRMODE_WARNING 警告1.7 单例模式封装MyPDO类1.7.1 步骤1、单例模式2、初始化参数3、连接数据库4、执行增删改5、执行查询 a)返回二维数组 b)返回一维数组 c)返回一行一列1.7.2 代码实现第一部分:单例、初始化参数、实例化PDO<?php class MyPDO{ private $type; //数据库类别 private $host; //主机地址 private $port; //端口号 private $dbname; //数据库名 private $charset; //字符集 private $user; //用户名 private $pwd; //密码 private $pdo; //保存PDO对象 private static $instance; private function __construct($param) { $this->initParam($param); $this->initPDO(); } private function __clone() { } public static function getInstance($param=array()){ if(!self::$instance instanceof self) self::$instance=new self($param); return self::$instance; } //初始化参数 private function initParam($param){ $this->type=$param['type']??'mysql'; $this->host=$param['host']??'127.0.0.1'; $this->port=$param['port']??'3306'; $this->dbname=$param['dbname']??'data'; $this->charset=$param['charset']??'utf8'; $this->user=$param['user']??'root'; $this->pwd=$param['pwd']??'root'; } //初始化PDO private function initPDO(){ try{ $dsn="{$this->type}:host={$this->host};port={$this->port};dbname={$this->dbname};charset={$this->charset}"; $this->pdo=new PDO($dsn, $this->user, $this->pwd); } catch (PDOException $ex) { echo '错误编号:'.$ex->getCode(),'<br>'; echo '错误行号:'.$ex->getLine(),'<br>'; echo '错误文件:'.$ex->getFile(),'<br>'; echo '错误信息:'.$ex->getMessage(),'<br>'; exit; } } } //测试 $param=array( ); $mypdo= MyPDO::getInstance($param); var_dump($mypdo);第二部分:数据操作部分<?php class MyPDO{ private $type; //数据库类别 private $host; //主机地址 private $port; //端口号 private $dbname; //数据库名 private $charset; //字符集 private $user; //用户名 private $pwd; //密码 private $pdo; //保存PDO对象 private static $instance; private function __construct($param) { $this->initParam($param); $this->initPDO(); $this->initException(); } private function __clone() { } public static function getInstance($param=array()){ if(!self::$instance instanceof self) self::$instance=new self($param); return self::$instance; } //初始化参数 private function initParam($param){ $this->type=$param['type']??'mysql'; $this->host=$param['host']??'127.0.0.1'; $this->port=$param['port']??'3306'; $this->dbname=$param['dbname']??'data'; $this->charset=$param['charset']??'utf8'; $this->user=$param['user']??'root'; $this->pwd=$param['pwd']??'root'; } //初始化PDO private function initPDO(){ try{ $dsn="{$this->type}:host={$this->host};port={$this->port};dbname={$this->dbname};charset={$this->charset}"; $this->pdo=new PDO($dsn, $this->user, $this->pwd); } catch (PDOException $ex) { $this->showException($ex); exit; } } //显示异常 private function showException($ex,$sql=''){ if($sql!=''){ echo 'SQL语句执行失败<br>'; echo '错误的SQL语句是:'.$sql,'<br>'; } echo '错误编号:'.$ex->getCode(),'<br>'; echo '错误行号:'.$ex->getLine(),'<br>'; echo '错误文件:'.$ex->getFile(),'<br>'; echo '错误信息:'.$ex->getMessage(),'<br>'; } //设置异常模式 private function initException(){ $this->pdo->setAttribute(PDO::ATTR_ERRMODE,PDO::ERRMODE_EXCEPTION); } //执行增、删、改操作 public function exec($sql){ try{ return $this->pdo->exec($sql); } catch (PDOException $ex) { $this->showException($ex, $sql); exit; } } //获取自动增长的编号 public function lastInsertId(){ return $this->pdo->lastInsertId(); } } //测试 $param=array( ); $mypdo= MyPDO::getInstance($param); //echo $mypdo->exec('delete from news where id=6'); if($mypdo->exec("insert into news values (null,'11','1111',unix_timestamp())")) echo '自动增长的编号是:'.$mypdo->lastInsertId ();第三部分:数据查询部分<?php class MyPDO{ ... //判断匹配的类型 private function fetchType($type){ switch ($type){ case 'num': return PDO::FETCH_NUM; case 'both': return PDO::FETCH_BOTH; case 'obj': return PDO::FETCH_OBJ; default: return PDO::FETCH_ASSOC; } } //获取所有数据 ,返回二维数组 public function fetchAll($sql,$type='assoc'){ try{ $stmt=$this->pdo->query($sql); //获取PDOStatement对象 $type= $this->fetchType($type); //获取匹配方法 return $stmt->fetchAll($type); } catch (Exception $ex) { $this->showException($ex, $sql); } } //获取一维数组 public function fetchRow($sql,$type='assoc'){ try{ $stmt=$this->pdo->query($sql); //获取PDOStatement对象 $type= $this->fetchType($type); //获取匹配方法 return $stmt->fetch($type); } catch (Exception $ex) { $this->showException($ex, $sql); exit; } } //返回一行一列 public function fetchColumn($sql){ try{ $stmt=$this->pdo->query($sql); return $stmt->fetchColumn(); } catch (Exception $ex) { $this->showException($ex, $sql); exit; } } } //测试 $param=array( ); $mypdo= MyPDO::getInstance($param); //echo $mypdo->exec('delete from news where id=6'); /* if($mypdo->exec("insert into news values (null,'11','1111',unix_timestamp())")) echo '自动增长的编号是:'.$mypdo->lastInsertId (); */ //$list=$mypdo->fetchAll('select * from news'); //$list=$mypdo->fetchRow('select * from news where id=1'); $list=$mypdo->fetchColumn('select count(*) from news'); echo '<pre>'; var_dump($list);
-
MySQL数据库(五)-数据备份和封装 1.1 目标理解数据备份与还原的重要性;掌握mysqldump.exe备份方式;掌握SQL备份后的还原方式;掌握Mysqli操作MySQL服务器的过程;掌握PHP利用Mysqli实现数据表的增删改查操作掌握PHP操作数据库的封装含义及意义能够实现新增新闻入库;能够实现更新新闻信息能够实现删除新闻信息能够实现显示新闻列表1.2 连接数据库通过PHP做MySQL的客户端1.2.1 开启mysqli扩展在php.ini中开启mysqli扩展extension=php_mysqli.dll开启扩展后重启服务器,就可以使用mysqli_函数了,1.2.2 连接数据库创建news数据库-- 创建表 drop table if exists news; create table news( id int unsigned auto_increment primary key comment '主键', title varchar(20) not null comment '标题', content text not null comment '内容', createtime int not null comment '添加时间' )engine=innodb charset=utf8 comment '新闻表'; -- 插入测试数据 insert into news values (null,'锄禾','锄禾日当午',unix_timestamp()); insert into news values (null,'草','离离原上草',unix_timestamp());思考:时间字段可以用datetime类型,也可以使用int类型。一般用int,因为datetime占用8个字节,int占用4个字节。连接数据库mysqli_connect(主机IP,用户名,密码,数据库名,端口号) //如果端口号是3306可以省略 mysqli_connect_error():获取连接数据库的错误信息 mysqli_connect_errno():获取连接数据库的错误编码 mysqli_set_charset(连接对象,字符编码) 代码如下:<?php //连接数据库,连接成功返回连接对象 $link=@mysqli_connect('localhost','root','root','data','3306'); //var_dump($link); //object(mysqli) if(mysqli_connect_error()){ echo '错误号:'.mysqli_connect_errno(),'<br>'; //显示错误编码 echo '错误信息:'.mysqli_connect_error(); //显示错误信息 exit; } //设置字符编码 mysqli_set_charset($link,'utf8'); 脚下留心:与数据库相关用utf8,与页面显示相关用utf-81.3 操作数据1.3.1 数据操作语句通过mysqli_query()执行SQL语句增、删、改语句执行成功返回true,失败返回false<?php //1、连接数据库 $link=mysqli_connect('localhost','root','root','data'); //2、设置支付编码 mysqli_set_charset($link,'utf8'); //3、执行SQL语句 //3.1 执行insert语句 /* $rs=mysqli_query($link,"insert into news values (null,'静夜思','床前明月光',unix_timestamp())"); if($rs) echo '自动增长的编号是:'.mysqli_insert_id($link); */ //3.2 执行update语句 /* $rs=mysqli_query($link,"update news set content='疑是地上霜' where id=4"); if($rs) echo '受影响的记录数是:'.mysqli_affected_rows($link); else{ echo '错误码:'.mysqli_errno($link),'<br>'; echo '错误信息:'.mysqli_error($link); } */ //3.3 执行delete语句 mysqli_query($link,"delete from news where id=5"); 用到的函数mysqli_query():执行SQL语句 mysqli_insert_id():获取插入记录自动增长的ID mysqli_affected_rows():获取受影响的记录数 mysqli_error():获取执行SQL语句的错误信息 mysqli_errno():获取执行SQL语句的错误码1.3.2 数据查询语句数据查询用select、desc、show,成功会返回结果集,失败返回false<?php //1、连接数据库 $link=@mysqli_connect('localhost','root','root','data') or die('错误信息:'.mysqli_connect_error()); //2、设置字符编码 mysqli_query($link,'set names utf8'); //3、执行查询语句 $rs=mysqli_query($link,'select * from news'); //var_dump($rs); //object(mysqli_result) //4、获取对象中的数据 //4.1 将对象中的一条数据匹配成索引数组,指针下移一条 //$rows=mysqli_fetch_row($rs); //4.2 将对象中的一条数据匹配成关联数组,指针下移一条 //$rows=mysqli_fetch_assoc($rs); //4.3 将对象中的一条数据匹配成索引,关联数组,指针下移一条 //$rows=mysqli_fetch_array($rs); //4.4 总列数、总行数 //echo '总行数'.mysqli_num_rows($rs),'<br>'; //echo '总列数'.mysqli_num_fields($rs),'<br>'; //4.5 获取所有数据 //$list=mysqli_fetch_all($rs); //默认是索引数组 //$list=mysqli_fetch_all($rs,MYSQLI_NUM); //匹配成索引数组 //$list=mysqli_fetch_all($rs,MYSQLI_ASSOC); //匹配成关联数组 $list=mysqli_fetch_all($rs,MYSQLI_BOTH); //匹配成关联、索引数组 echo '<pre>'; print_r($list); //5、销毁结果集 mysqli_free_result($rs); //6、关闭连接 mysqli_close($link); 使用的函数mysqli_fetch_assoc():将一条数组匹配关联数组 mysqli_fetch_row():将一条记录匹配成索引数组 mysqli_fetch_array():将一条记录匹配成既有关联数组又有索引数组 mysqli_fetch_all():匹配所有记录 mysqli_num_rows():总行数 mysqli_num_fields():总记录数 mysqli_free_result():销毁结果集 mysqli_close():关闭连接1.4 新闻模块1.4.1 包含文件由于所有的操作都要连接数据库,将连接数据库的代码存放到包含文件中步骤1、在站点下创建inc文件夹2、在inc下创建conn.php文件,用来连接数据库,代码就是上面连接数据库的代码代码实现<?php //连接数据库 $link=@mysqli_connect('localhost','root','root','data') or die('错误:'.mysqli_connect_error()); mysqli_set_charset($link,'utf8');1.4.2 显示新闻步骤:1、连接数据库2、获取数据3、遍历循环数据代码<style type="text/css"> table{ width:780px; border:solid 1px #000; margin:auto; } th,td{ border:solid 1px #000; } </style> <body> <?php //1、连接数据库 require './inc/conn.php'; //2、获取数据 $rs=mysqli_query($link,'select * from news order by id desc'); //返回结果集对象 $list=mysqli_fetch_all($rs,MYSQLI_ASSOC); //将结果匹配成关联数组 ?> <table> <tr> <th>编号</th> <th>标题</th> <th>内容</th> <th>时间</th> <th>修改</th> <th>删除</th> <!--3、循环显示数据--> <?php foreach($list as $rows):?> <tr> <td><?php echo $rows['id']?></td> <td><?php echo $rows['title']?></td> <td><?php echo $rows['content']?></td> <td><?php echo date('Y-m-d H:i:s',$rows['createtime'])?></td> <td><input type="button" value="修改" onclick=""></td> <td><input type="button" value="删除" onclick=""></td> </tr> <?php endforeach;?> </tr> </table> </body>运行结果1.4.3 添加新闻步骤:1、创建表单2、连接数据库3、将新闻数据写入到数据库中入口(list.php)<a href="./add.php">添加新闻</a>代码实现<body> <?php if(!empty($_POST)) { //2、连接数据库 require './inc/conn.php'; //3、插入数据 $time=time(); //获取时间戳 $sql="insert into news values (null,'{$_POST['title']}','{$_POST['content']}',$time)"; //拼接SQL语句 if(mysqli_query($link,$sql)) //执行SQL语句 header('location:./list.php'); //插入成功就跳转到list.php页面 else{ echo 'SQL语句插入失败<br>'; echo '错误码:'.mysqli_errno($link),'<br>'; echo '错误信息:'.mysqli_error($link); } } ?> <!--1、创建表单--> <form method="post" action=""> 标题: <input type="text" name="title"> <br /> <br /> 内容: <textarea name="content" rows="5" cols="30"></textarea> <br /> <br /> <input type="submit" name="button" value="提交"> </form> </body>运行结果1.4.4 删除新闻步骤:1、在list.php页面点击删除按钮,跳转到del.php页面,传递删除的id2、在del.php页面连接数据库3、通过id删除数据4、删除成功后,跳转到list.php入口(list.php)<input type="button" value="删除" onclick="if(confirm('确定要删除吗'))location.href='./del.php?id=<?php echo $rows['id']?>'">del.php<?php //1、连接数据库 require './inc/conn.php'; //2、拼接SQL语句 $sql="delete from news where id={$_GET['id']}"; //3、执行SQL语句 if(mysqli_query($link,$sql)) header('location:./list.php'); else{ echo '删除失败'; }小结:1、一个页面是否写HTML架构,取决于是否有显示功能。2、如果一个页面只是做业务逻辑,没有显示功能,就不需要写HTML架构,比如del.php页面1.4.5 修改新闻入口(list.php)<input type="button" value="修改" onclick="location.href='edit.php?id=<?php echo $rows['id']?>'">edit.php页面步骤第一步:显示修改界面 1、连接数据库 2、获取修改的数据 3、将数据显示到表单中第二步:执行修改逻辑 1、获取新数据 2、拼接修改的SQL语句,执行修改逻辑代码如下<?php //连接数据库 require './inc/conn.php'; //1、获取修改的数据库 $sql="select * from news where id={$_GET['id']}"; //拼接SQL语句 $rs=mysqli_query($link,$sql); //获取修改的数据 $rows=mysqli_fetch_assoc($rs); //将修改的数据匹配成一维关联数组 //2、执行修改的逻辑 if(!empty($_POST)) { $id=$_GET['id']; //获取修改的id $title=$_POST['title']; //修改的标题 $content=$_POST['content']; //修改的内容 $sql="update news set title='$title',content='$content' where id=$id"; //拼接SQL语句 if(mysqli_query($link,$sql)) header('location:list.php'); //修改成功跳转到list.php页面 else echo '错误:'.mysqli_error($link); exit; } ?> <!doctype html> <html> <head> <meta charset="utf-8"> <title>无标题文档</title> </head> <body> <form method="post" action=""> 标题: <input type="text" name="title" value='<?php echo $rows['title']?>'> <br /> <br /> 内容: <textarea name="content" rows="5" cols="30"><?php echo $rows['content']?></textarea> <br /> <br /> <input type="submit" name="button" value="提交"> <input type="button" value="返回" onclick="location.href='list.php'"> </form> </body> </html>运行结果1.5 数据备份与还原数据库中的数据需要定期备份,数据量小的可以一周备份一次,数据量的可以一天备份一次。1.5.1 数据备份利用mysqldump工具,语法:mysqldump 数据库连接 数据库 > SQL文件备份地址例题:-- 将data数据库中所有的表导出到data.sql中 F:\wamp\PHPTutorial\MySQL\bin>mysqldump -uroot -proot data>c:\data.sql -- 将data数据库中的stuinfo、stumarks表 F:\wamp\PHPTutorial\MySQL\bin>mysqldump -uroot -proot data stuinfo stumarks>c:\data.sql -- 导出data数据库,导出的语句中带有创建数据库的语法 F:\wamp\PHPTutorial\MySQL\bin>mysqldump -uroot -proot -B data>c:\data1.sql1.5.2 数据还原方法一:MySQL的source指令(需要登录MySQL才能使用)mysql> source c:/data.sql; 注意:地址分隔符用斜线,不能用反斜线方法二:通过mysql指令数据还原(不需要登录MySQL)语法:mysql 连接数据库 导入的数据库名 < 导入的SQL文件例题:F:\wamp\PHPTutorial\MySQL\bin>mysql -uroot -proot data1 < c:\data.sql1.6 作业:1、通过循环的方式获取表中的所有记录2、通过异步实现增、删、改异步添加add.html<body> <script src='./js/jquery-3.3.1.min.js'></script> <script> $(document).ready(function() { $(':button:first').click(function(){ var title=$('#title').val(); var content=$('#content').val(); $.post('./add.php',{'title':title,'content':content},function(data){ if(data){ alert('添加成功'); location.href='list.php'; }else{ alert('添加失败'); } }) }) }); </script> <!--1、创建表单--> <form method="post" action=""> 标题: <input type="text" id="title"> <br /> <br /> 内容: <textarea id="content" rows="5" cols="30"></textarea> <br /> <br /> <input type="button" name="button" value="提交"> </form> </body>add.php<?php require './inc/conn.php'; $title=$_POST['title']; $content=$_POST['content']; $time=time(); $sql="insert into news values (null,'$title','$content',$time)"; echo mysqli_query($link,$sql)?1:0;异步删除list.php-- button按钮 <td><input type="button" value="删除" op='del' newsid=<?php echo $rows['id']?>></td> <script src='./js/jquery-3.3.1.min.js'></script> <script> $(document).ready(function() { $(':button').click(function(){ var tr=$(this).parents('tr'); //按钮所在的行 if($(this).attr('op')=='del'){ var id=$(this).attr('newsid'); //获取新闻的id $.post('./del.php',{'id':id},function(data){ if(data==1) tr.remove(); else alert('删除失败'); }) } }) }); </script>del.php<?php //1、连接数据库 require './inc/conn.php'; //2、拼接SQL语句 $sql="delete from news where id={$_POST['id']}"; //3、执行SQL语句 echo mysqli_query($link,$sql)?1:0;
-
MySQL 数据库(四)-多表查询、子查询、预处理和事务 1.1 目标理解查询五子句的顺序关系;掌握两张表的联合查询方法;理解连接查询的原理;掌握子查询的使用方式;掌握预处理的实现步骤;理解事务的基本工作原理;掌握事务的四个特点;理解视图的概念和作用;1.2 多表查询1.2.1 内连接规则:返回两个表的公共记录语法:-- 语法一 select * from 表1 inner join 表2 on 表1.公共字段=表2.公共字段 -- 语法二 select * from 表1,表2 where 表1.公共字段=表2.公共字段 例题-- inner join mysql> select * from stuinfo inner join stumarks on stuinfo.stuno=stumarks.stuno; +--------+----------+--------+--------+---------+------------+---------+--------+-------------+---------+ | stuNo | stuName | stuSex | stuAge | stuSeat | stuAddress | examNo | stuNo | writtenExam | labExam | +--------+----------+--------+--------+---------+------------+---------+--------+-------------+---------+ | s25303 | 李斯文 | 女 | 22 | 2 | 北京 | s271811 | s25303 | 80 | 58 | | s25302 | 李文才 | 男 | 31 | 3 | 上海 | s271813 | s25302 | 50 | 90 | | s25304 | 欧阳俊雄 | 男 | 28 | 4 | 天津 | s271815 | s25304 | 65 | 50 | | s25301 | 张秋丽 | 男 | 18 | 1 | 北京 | s271816 | s25301 | 77 | 82 | | s25318 | 争青小子 | 男 | 26 | 6 | 天津 | s271819 | s25318 | 56 | 48 | +--------+----------+--------+--------+---------+------------+---------+--------+-------------+---------+ 5 rows in set (0.00 sec) -- 相同的字段只显示一次 mysql> select s.stuno,stuname,stusex,writtenexam,labexam from stuinfo s inner join stumarks m on s.stuno=m.stuno; +--------+----------+--------+-------------+---------+ | stuno | stuname | stusex | writtenexam | labexam | +--------+----------+--------+-------------+---------+ | s25303 | 李斯文 | 女 | 80 | 58 | | s25302 | 李文才 | 男 | 50 | 90 | | s25304 | 欧阳俊雄 | 男 | 65 | 50 | | s25301 | 张秋丽 | 男 | 77 | 82 | | s25318 | 争青小子 | 男 | 56 | 48 | +--------+----------+--------+-------------+---------+ 5 rows in set (0.00 sec) -- 使用where mysql> select * from stuinfo,stumarks where stuinfo.stuno=stumarks.stuno; +--------+----------+--------+--------+---------+------------+---------+--------+-------------+---------+ | stuNo | stuName | stuSex | stuAge | stuSeat | stuAddress | examNo | stuNo | writtenExam | labExam | +--------+----------+--------+--------+---------+------------+---------+--------+-------------+---------+ | s25303 | 李斯文 | 女 | 22 | 2 | 北京 | s271811 | s25303 | 80 | 58 | | s25302 | 李文才 | 男 | 31 | 3 | 上海 | s271813 | s25302 | 50 | 90 | | s25304 | 欧阳俊雄 | 男 | 28 | 4 | 天津 | s271815 | s25304 | 65 | 50 | | s25301 | 张秋丽 | 男 | 18 | 1 | 北京 | s271816 | s25301 | 77 | 82 | | s25318 | 争青小子 | 男 | 26 | 6 | 天津 | s271819 | s25318 | 56 | 48 | +--------+----------+--------+--------+---------+------------+---------+--------+-------------+---------+ 5 rows in set (0.00 sec)多学一招:-- 1、内连接中inner可以省略 select * from 表1 join 表2 on 表1.公共字段=表2.公共字段 mysql> select * from stuinfo join stumarks on stuinfo.stuno=stumarks.stuno; +--------+----------+--------+--------+---------+------------+---------+--------+-------------+---------+ | stuNo | stuName | stuSex | stuAge | stuSeat | stuAddress | examNo | stuNo | writtenExam | labExam | +--------+----------+--------+--------+---------+------------+---------+--------+-------------+---------+ | s25303 | 李斯文 | 女 | 22 | 2 | 北京 | s271811 | s25303 | 80 | 58 | | s25302 | 李文才 | 男 | 31 | 3 | 上海 | s271813 | s25302 | 50 | 90 | | s25304 | 欧阳俊雄 | 男 | 28 | 4 | 天津 | s271815 | s25304 | 65 | 50 | | s25301 | 张秋丽 | 男 | 18 | 1 | 北京 | s271816 | s25301 | 77 | 82 | | s25318 | 争青小子 | 男 | 26 | 6 | 天津 | s271819 | s25318 | 56 | 48 | +--------+----------+--------+--------+---------+------------+---------+--------+-------------+---------+ 5 rows in set (0.00 sec) -- 如何实现三表查询 select * from 表1 inner join 表2 on 表1.公共字段=表2.公共字段 inner join 表3 on 表2.公共字段=表3.公共字段 -- 表连接越多,效率越低思考:select * from 表1 inner join 表2 on 表1.公共字段=表2.公共字段 和 select * from 表2 inner join 表1 on 表1.公共字段=表2.公共字段 一样吗? 答:一样的1.2.2 左外连接规则:以左边的表为准,右边如果没有对应的记录用null显示语法:select * from 表1 left join 表2 on 表1.公共字段=表2.公共字段例题:mysql> select stuname,writtenexam,labexam from stuinfo left join stumarks on stuinfo.stuno=stumarks.stuno; +----------+-------------+---------+ | stuname | writtenexam | labexam | +----------+-------------+---------+ | 张秋丽 | 77 | 82 | | 李文才 | 50 | 90 | | 李斯文 | 80 | 58 | | 欧阳俊雄 | 65 | 50 | | 诸葛丽丽 | NULL | NULL | | 争青小子 | 56 | 48 | | 梅超风 | NULL | NULL | +----------+-------------+---------+ 7 rows in set (0.01 sec)思考:select * from 表1 left join 表2 on 表1.公共字段=表2.公共字段 和 select * from 表2 left join 表1 on 表1.公共字段=表2.公共字段 一样吗? 答:不一样,第一个SQL以表1为准,第二个SQL以表2为准。1.2.3 右外连接规则:以右边的表为准,左边如果没有对应的记录用null显示语法:select * from 表1 right join 表2 on 表1.公共字段=表2.公共字段例题:mysql> select stuname,writtenexam,labexam from stuinfo right join stumarks on stuinfo.stuno=stumarks.stuno; +----------+-------------+---------+ | stuname | writtenexam | labexam | +----------+-------------+---------+ | 李斯文 | 80 | 58 | | 李文才 | 50 | 90 | | 欧阳俊雄 | 65 | 50 | | 张秋丽 | 77 | 82 | | 争青小子 | 56 | 48 | | NULL | 66 | 77 | +----------+-------------+---------+ 6 rows in set (0.00 sec)思考select * from 表1 left join 表2 on 表1.公共字段=表2.公共字段 和 select * from 表2 right join 表1 on 表1.公共字段=表2.公共字段 一样吗? 答:一样1.2.4 交叉连接语法,返回笛卡尔积select * from 表1 cross join 表2例题-- 交叉连接 mysql> select * from stuinfo cross join stumarks; -- 交叉连接有连接表达式与内连接是一样的 mysql> select * from stuinfo cross join stumarks on stuinfo.stuno=stumarks.stuno; +--------+----------+--------+--------+---------+------------+---------+--------+-------------+---------+ | stuNo | stuName | stuSex | stuAge | stuSeat | stuAddress | examNo | stuNo | writtenExam | labExam | +--------+----------+--------+--------+---------+------------+---------+--------+-------------+---------+ | s25303 | 李斯文 | 女 | 22 | 2 | 北京 | s271811 | s25303 | 80 | 58 | | s25302 | 李文才 | 男 | 31 | 3 | 上海 | s271813 | s25302 | 50 | 90 | | s25304 | 欧阳俊雄 | 男 | 28 | 4 | 天津 | s271815 | s25304 | 65 | 50 | | s25301 | 张秋丽 | 男 | 18 | 1 | 北京 | s271816 | s25301 | 77 | 82 | | s25318 | 争青小子 | 男 | 26 | 6 | 天津 | s271819 | s25318 | 56 | 48 | +--------+----------+--------+--------+---------+------------+---------+--------+-------------+---------+ 5 rows in set (0.00 sec)小结1、交叉连接如果没有连接条件返回笛卡尔积2、如果有连接条件和内连接是一样的。1.2.5 自然连接自动判断条件连接,判断的条件是依据同名字段1、自然内连接(natural join)mysql> select * from stuinfo natural join stumarks; +--------+----------+--------+--------+---------+------------+---------+-------------+---------+ | stuNo | stuName | stuSex | stuAge | stuSeat | stuAddress | examNo | writtenExam | labExam | +--------+----------+--------+--------+---------+------------+---------+-------------+---------+ | s25303 | 李斯文 | 女 | 22 | 2 | 北京 | s271811 | 80 | 58 | | s25302 | 李文才 | 男 | 31 | 3 | 上海 | s271813 | 50 | 90 | | s25304 | 欧阳俊雄 | 男 | 28 | 4 | 天津 | s271815 | 65 | 50 | | s25301 | 张秋丽 | 男 | 18 | 1 | 北京 | s271816 | 77 | 82 | | s25318 | 争青小子 | 男 | 26 | 6 | 天津 | s271819 | 56 | 48 | +--------+----------+--------+--------+---------+------------+---------+-------------+---------+ 5 rows in set (0.00 sec)2、自然左外连接(natural left join)mysql> select * from stuinfo natural left join stumarks; +--------+----------+--------+--------+---------+------------+---------+-------------+---------+ | stuNo | stuName | stuSex | stuAge | stuSeat | stuAddress | examNo | writtenExam | labExam | +--------+----------+--------+--------+---------+------------+---------+-------------+---------+ | s25301 | 张秋丽 | 男 | 18 | 1 | 北京 | s271816 | 77 | 82 | | s25302 | 李文才 | 男 | 31 | 3 | 上海 | s271813 | 50 | 90 | | s25303 | 李斯文 | 女 | 22 | 2 | 北京 | s271811 | 80 | 58 | | s25304 | 欧阳俊雄 | 男 | 28 | 4 | 天津 | s271815 | 65 | 50 | | s25305 | 诸葛丽丽 | 女 | 23 | 7 | 河南 | NULL | NULL | NULL | | s25318 | 争青小子 | 男 | 26 | 6 | 天津 | s271819 | 56 | 48 | | s25319 | 梅超风 | 女 | 23 | 5 | 河北 | NULL | NULL | NULL | +--------+----------+--------+--------+---------+------------+---------+-------------+---------+ 7 rows in set (0.00 sec)3、自然右外连接(natural right join)mysql> select * from stuinfo natural right join stumarks; +--------+---------+-------------+---------+----------+--------+--------+---------+------------+ | stuNo | examNo | writtenExam | labExam | stuName | stuSex | stuAge | stuSeat | stuAddress | +--------+---------+-------------+---------+----------+--------+--------+---------+------------+ | s25303 | s271811 | 80 | 58 | 李斯文 | 女 | 22 | 2 | 北京 | | s25302 | s271813 | 50 | 90 | 李文才 | 男 | 31 | 3 | 上海 | | s25304 | s271815 | 65 | 50 | 欧阳俊雄 | 男 | 28 | 4 | 天津 | | s25301 | s271816 | 77 | 82 | 张秋丽 | 男 | 18 | 1 | 北京 | | s25318 | s271819 | 56 | 48 | 争青小子 | 男 | 26 | 6 | 天津 | | s25320 | s271820 | 66 | 77 | NULL | NULL | NULL | NULL | NULL | +--------+---------+-------------+---------+----------+--------+--------+---------+------------+ 6 rows in set (0.00 sec)小结:1、表连接是通过同名字段来连接的2、如果没有同名字段就返回笛卡尔积3、同名的连接字段只显示一个,并且将该字段放在最前面1.2.6 usingusing用来指定连接字段mysql> select * from stuinfo inner join stumarks using(stuno); +--------+----------+--------+--------+---------+------------+---------+-------------+---------+ | stuNo | stuName | stuSex | stuAge | stuSeat | stuAddress | examNo | writtenExam | labExam | +--------+----------+--------+--------+---------+------------+---------+-------------+---------+ | s25303 | 李斯文 | 女 | 22 | 2 | 北京 | s271811 | 80 | 58 | | s25302 | 李文才 | 男 | 31 | 3 | 上海 | s271813 | 50 | 90 | | s25304 | 欧阳俊雄 | 男 | 28 | 4 | 天津 | s271815 | 65 | 50 | | s25301 | 张秋丽 | 男 | 18 | 1 | 北京 | s271816 | 77 | 82 | | s25318 | 争青小子 | 男 | 26 | 6 | 天津 | s271819 | 56 | 48 | +--------+----------+--------+--------+---------+------------+---------+-------------+---------+ 5 rows in set (0.00 sec)using的结果也会对公共字段进行优化,优化的规则和自然连接是一样的;1.2.7 练习1、显示地区及每个地区参加笔试的人数,并按人数降序排列-- 第一步: 显示地区及每个地区参加笔试的人数 mysql> select stuaddress,count(writtenexam) from stuinfo left join stumarks using(stuno) group by stuaddress; +------------+--------------------+ | stuaddress | count(writtenexam) | +------------+--------------------+ | 上海 | 1 | | 北京 | 2 | | 天津 | 2 | | 河北 | 0 | | 河南 | 0 | +------------+--------------------+ 5 rows in set (0.00 sec) -- 第二步:将结果降序排列 mysql> select stuaddress,count(writtenexam) c from stuinfo left join stumarks using(stuno) group by stuaddress order by c desc; +------------+---+ | stuaddress | c | +------------+---+ | 北京 | 2 | | 天津 | 2 | | 上海 | 1 | | 河北 | 0 | | 河南 | 0 | +------------+---+ 5 rows in set (0.00 sec)2、显示有学生参加考试的地区-- having筛选 mysql> select stuaddress,count(writtenexam) c from stuinfo left join stumarks using(stuno) group by stuaddress having c>0; +------------+---+ | stuaddress | c | +------------+---+ | 上海 | 1 | | 北京 | 2 | | 天津 | 2 | +------------+---+ 3 rows in set (0.00 sec) -- 表连接实现 -- 第一步:右连接获取有成绩的地区 mysql> select stuaddress from stuinfo right join stumarks using(stuno); +------------+ | stuaddress | +------------+ | 北京 | | 上海 | | 天津 | | 北京 | | 天津 | | NULL | +------------+ 6 rows in set (0.00 sec) -- 第二步:去重复 mysql> select distinct stuaddress from stuinfo right join stumarks using(stuno); +------------+ | stuaddress | +------------+ | 北京 | | 上海 | | 天津 | | NULL | +------------+ 4 rows in set (0.00 sec) -- 去除null mysql> select distinct stuaddress from stuinfo right join stumarks using(stuno) having stuaddress is not null; +------------+ | stuaddress | +------------+ | 北京 | | 上海 | | 天津 | +------------+ 3 rows in set (0.00 sec)3、显示男生和女生的人数-- 方法一: 分组查询 mysql> select stusex,count(*) from stuinfo group by stusex; +--------+----------+ | stusex | count(*) | +--------+----------+ | 女 | 3 | | 男 | 4 | +--------+----------+ 2 rows in set (0.00 sec) -- 方法二: union mysql> select stusex,count(*) from stuinfo where stusex='男' union select stusex,count(*) from stuinfo where stusex='女'; +--------+----------+ | stusex | count(*) | +--------+----------+ | 男 | 4 | | 女 | 3 | +--------+----------+ 2 rows in set (0.00 sec) -- 方法三:直接写条件 mysql> select sum(stusex='男') 男,sum(stusex='女') 女 from stuinfo; +------+------+ | 男 | 女 | +------+------+ | 4 | 3 | +------+------+ 1 row in set (0.00 sec)4、显示每个地区男生、女生、总人数mysql> select stuaddress,count(*) 总人数,sum(stusex='男') 男,sum(stusex='女') 女 from stuinfo group by stuaddress; +------------+--------+------+------+ | stuaddress | 总人数 | 男 | 女 | +------------+--------+------+------+ | 上海 | 1 | 1 | 0 | | 北京 | 2 | 1 | 1 | | 天津 | 2 | 2 | 0 | | 河北 | 1 | 0 | 1 | | 河南 | 1 | 0 | 1 | +------------+--------+------+------+ 5 rows in set (0.00 sec)1.3 子查询语法:select * from 表1 where (子查询)外面的查询称为父查询子查询为父查询提供查询条件1.3.1 标量子查询特点:子查询返回的值是一个-- 查找笔试成绩是80的学生 mysql> select * from stuinfo where stuno=(select stuno from stumarks where writtenexam=80); +--------+---------+--------+--------+---------+------------+ | stuNo | stuName | stuSex | stuAge | stuSeat | stuAddress | +--------+---------+--------+--------+---------+------------+ | s25303 | 李斯文 | 女 | 22 | 2 | 北京 | +--------+---------+--------+--------+---------+------------+ 1 row in set (0.00 sec) -- 查找最高分的学生 -- 方法一 mysql> select * from stuinfo where stuno=(select stuno from stumarks order by writtenexam desc limit 1); +--------+---------+--------+--------+---------+------------+ | stuNo | stuName | stuSex | stuAge | stuSeat | stuAddress | +--------+---------+--------+--------+---------+------------+ | s25303 | 李斯文 | 女 | 22 | 2 | 北京 | +--------+---------+--------+--------+---------+------------+ 1 row in set (0.00 sec) -- 方法二: mysql> select * from stuinfo where stuno=(select stuno from stumarks where writtenexam=(select max(writtenexam) from stumarks)) +--------+---------+--------+--------+---------+------------+ | stuNo | stuName | stuSex | stuAge | stuSeat | stuAddress | +--------+---------+--------+--------+---------+------------+ | s25303 | 李斯文 | 女 | 22 | 2 | 北京 | +--------+---------+--------+--------+---------+------------+ 1 row in set (0.00 sec)1.3.2 列子查询特点: 子查询返回的结果是一列如果子查询的结果返回多条记录,不能使用等于,用in或not in-- 查找及格的同学 mysql> select * from stuinfo where stuno in (select stuno from stumarks where writtenexam>=60); +--------+----------+--------+--------+---------+------------+ | stuNo | stuName | stuSex | stuAge | stuSeat | stuAddress | +--------+----------+--------+--------+---------+------------+ | s25301 | 张秋丽 | 男 | 18 | 1 | 北京 | | s25303 | 李斯文 | 女 | 22 | 2 | 北京 | | s25304 | 欧阳俊雄 | 男 | 28 | 4 | 天津 | +--------+----------+--------+--------+---------+------------+ 3 rows in set (0.00 sec) -- 查询不及格的同学 mysql> select * from stuinfo where stuno in (select stuno from stumarks where writtenexam<60); +--------+----------+--------+--------+---------+------------+ | stuNo | stuName | stuSex | stuAge | stuSeat | stuAddress | +--------+----------+--------+--------+---------+------------+ | s25302 | 李文才 | 男 | 31 | 3 | 上海 | | s25318 | 争青小子 | 男 | 26 | 6 | 天津 | +--------+----------+--------+--------+---------+------------+ 2 rows in set (0.00 sec) -- 查询需要补考的学生 mysql> select * from stuinfo where stuno not in (select stuno from stumarks where writtenexam>=60); +--------+----------+--------+--------+---------+------------+ | stuNo | stuName | stuSex | stuAge | stuSeat | stuAddress | +--------+----------+--------+--------+---------+------------+ | s25302 | 李文才 | 男 | 31 | 3 | 上海 | | s25305 | 诸葛丽丽 | 女 | 23 | 7 | 河南 | | s25318 | 争青小子 | 男 | 26 | 6 | 天津 | | s25319 | 梅超风 | 女 | 23 | 5 | 河北 | +--------+----------+--------+--------+---------+------------+ 4 rows in set (0.00 sec)1.3.3 行子查询特点:子查询返回的结果是多个字段组成-- 查找语文成绩最高的男生和女生 mysql> select * from stu where(stusex,ch) in (select stusex,max(ch) from stu group by stusex); +--------+----------+--------+--------+---------+------------+------+------+ | stuNo | stuName | stuSex | stuAge | stuSeat | stuAddress | ch | math | +--------+----------+--------+--------+---------+------------+------+------+ | s25318 | 争青小子 | 男 | 26 | 6 | 天津 | 86 | 92 | | s25321 | Tabm | 女 | 23 | 9 | 河北 | 88 | 77 | +--------+----------+--------+--------+---------+------------+------+------+ 2 rows in set (0.00 sec)1.3.4 表子查询特点:将子查询的结果作为表-- 查找语文成绩最高的男生和女生 mysql> select * from (select * from stu order by ch desc) t group by stusex; +--------+----------+--------+--------+---------+------------+------+------+ | stuNo | stuName | stuSex | stuAge | stuSeat | stuAddress | ch | math | +--------+----------+--------+--------+---------+------------+------+------+ | s25321 | Tabm | 女 | 23 | 9 | 河北 | 88 | 77 | | s25318 | 争青小子 | 男 | 26 | 6 | 天津 | 86 | 92 | +--------+----------+--------+--------+---------+------------+------+------+ 2 rows in set (0.00 sec)注意:from后面跟的是数据源,如果将子查询当成表来看, 必须给结果集取别名。1.3.5 exists子查询-- 如果笔试成绩有人超过80人,就显示所有学生信息 mysql> select * from stuinfo where exists (select * from stumarks where writtenexam>=80); -- 没有超过80的学生,就显示所有学生信息 mysql> select * from stuinfo where not exists (select * from stumarks where writtenexam>=80); Empty set (0.00 sec)作用:提高查询效率1.4 视图1.4.1 概述1、视图是一张虚拟表,它表示一张表的部分数据或多张表的综合数据,其结构和数据是建立在对表的查询基础上2、视图中并不存放数据,而是存放在视图所引用的原始表(基表)中3、同一张原始表,根据不同用户的不同需求,可以创建不同的视图1.4.2 作用1、筛选表中的行2、防止未经许可的用户访问敏感数据3、隐藏数据表的结构4、降低数据表的复杂程度1.4.3 创建视图语法:-- 创建视图 create view 视图名 as select 语句; -- 查询视图 select 列名 from 视图例题-- 创建视图 mysql> create view view1 -> as -> select * from stu where ch>=60 and math>=60; Query OK, 0 rows affected (0.00 sec) -- 查询视图 mysql> select * from view1; +--------+----------+--------+--------+---------+------------+------+------+ | stuNo | stuName | stuSex | stuAge | stuSeat | stuAddress | ch | math | +--------+----------+--------+--------+---------+------------+------+------+ | s25302 | 李文才 | 男 | 31 | 3 | 上海 | 77 | 76 | | s25318 | 争青小子 | 男 | 26 | 6 | 天津 | 86 | 92 | | s25319 | 梅超风 | 女 | 23 | 5 | 河北 | 74 | 67 | | s25320 | Tom | 男 | 24 | 8 | 北京 | 65 | 67 | | s25321 | Tabm | 女 | 23 | 9 | 河北 | 88 | 77 | +--------+----------+--------+--------+---------+------------+------+------+ 5 rows in set (0.02 sec) -- 视图可以使得降低SQL语句的复杂度 mysql> create view view2 -> as -> select stuno,stusex,writtenexam,labexam from stuinfo natural join stumarks; Query OK, 0 rows affected (0.01 sec)1.4.4 修改视图语法alter view 视图名 as select 语句例题:mysql> alter view view2 -> as -> select stuname from stuinfo; Query OK, 0 rows affected (0.00 sec)1.4.5 删除视图语法drop view [if exists ] 视图1,视图,...例题mysql> drop view view2; Query OK, 0 rows affected (0.00 sec)1.4.6 查看视图信息-- 方法一; mysql> show tables; -- 显示所有的表和视图 -- 方法二:精确查找视图(视图信息存储在information_schema下的views表中) mysql> select table_name from information_schema.views; +------------+ | table_name | +------------+ | view1 | +------------+ 1 row in set (0.05 sec) -- 方法三:通过表的comment属性查询视图 mysql> show table status\G; -- 查询所有表和视图的详细状态信息 mysql> show table status where comment='view'\G -- 只查找视图信息查询视图的结构mysql> desc view1;查询创建视图的语法mysql> show create view view1\G1.4.7 视图算法场景:找出语文成绩最高的男生和女生方法一:mysql> select * from (select * from stu order by ch desc) t group by stusex; +--------+----------+--------+--------+---------+------------+------+------+ | stuNo | stuName | stuSex | stuAge | stuSeat | stuAddress | ch | math | +--------+----------+--------+--------+---------+------------+------+------+ | s25321 | Tabm | 女 | 23 | 9 | 河北 | 88 | 77 | | s25318 | 争青小子 | 男 | 26 | 6 | 天津 | 86 | 92 | +--------+----------+--------+--------+---------+------------+------+------+ 2 rows in set (0.00 sec)方法二:mysql> create view view3 -> as -> select * from stu order by ch desc; Query OK, 0 rows affected (0.00 sec) mysql> select * from view3 group by stusex; +--------+---------+--------+--------+---------+------------+------+------+ | stuNo | stuName | stuSex | stuAge | stuSeat | stuAddress | ch | math | +--------+---------+--------+--------+---------+------------+------+------+ | s25301 | 张秋丽 | 男 | 18 | 1 | 北京 | 80 | NULL | | s25303 | 李斯文 | 女 | 22 | 2 | 北京 | 55 | 82 | +--------+---------+--------+--------+---------+------------+------+------+ 2 rows in set (0.00 sec)结论:方法一和方法二的结果不一样,这是因为视图的算法造成的。视图的算法有:1、merge:合并算法(将视图语句和外层语句合并后再执行)2、temptable:临时表算法(将视图作为一个临时表来执行)3、undefined:未定义算法(用哪种算法有MySQL决定,这是默认算法,视图一般会选merge算法)重新通过视图实现-- 创建视图,指定算法为临时表算法 mysql> create or replace algorithm=temptable view view3 -> as -> select * from stu order by ch desc; Query OK, 0 rows affected (0.00 sec) mysql> select * from view3 group by stusex; +--------+----------+--------+--------+---------+------------+------+------+ | stuNo | stuName | stuSex | stuAge | stuSeat | stuAddress | ch | math | +--------+----------+--------+--------+---------+------------+------+------+ | s25321 | Tabm | 女 | 23 | 9 | 河北 | 88 | 77 | | s25318 | 争青小子 | 男 | 26 | 6 | 天津 | 86 | 92 | +--------+----------+--------+--------+---------+------------+------+------+ 2 rows in set (0.00 sec)结论:和子查询结果一致。1.5 事务1.5.1 概述事务(TRANSACTION)是一个整体,要么一起执行,要么一起不执行1.5.2 事务特性事务必须具备以下四个属性,简称ACID 属性:原子性(Atomicity):事务是一个完整的操作。事务的各步操作是不可分的(原子的);要么都执行,要么都不执行一致性(Consistency):当事务完成时,数据必须处于一致状态隔离性(Isolation):对数据进行修改的所有并发事务是彼此隔离的。永久性(Durability):事务完成后,它对数据库的修改被永久保持。1.5.3 事务处理开启事务start transaction 或 begin [work]提交事务commit回滚事务rollback例题:-- 插入测试数据 mysql> create table bank( -> card char(4) primary key comment '卡号', -> money decimal(10,2) not null -> )engine=innodb charset=utf8; Query OK, 0 rows affected (0.05 sec) mysql> insert into bank values ('1001',1000),('1002',1); Query OK, 2 rows affected (0.00 sec) Records: 2 Duplicates: 0 Warnings: 0 -- 开启事务 mysql> begin; Query OK, 0 rows affected (0.00 sec) mysql> delimiter // -- 更改定界符 mysql> update bank set money=money-100 where card='1001'; -> update bank set money=money+100 where card='1002' // Query OK, 1 row affected (0.04 sec) Rows matched: 1 Changed: 1 Warnings: 0 -- 回滚事务 mysql> rollback // Query OK, 0 rows affected (0.00 sec) mysql> select * from bank // +------+---------+ | card | money | +------+---------+ | 1001 | 1000.00 | | 1002 | 1.00 | +------+---------+ 2 rows in set (0.00 sec) ------------------------------------------------------------------ -- 开启事务 mysql> start transaction // Query OK, 0 rows affected (0.00 sec) mysql> update bank set money=money-100 where card='1001'; -> update bank set money=money+100 where card='1002' // Query OK, 1 row affected (0.00 sec) Rows matched: 1 Changed: 1 Warnings: 0 -- 提交事务 mysql> commit // Query OK, 0 rows affected (0.00 sec) mysql> select * from bank // +------+--------+ | card | money | +------+--------+ | 1001 | 900.00 | | 1002 | 101.00 | +------+--------+设置事务的回滚点-- 开启事务 mysql> begin // Query OK, 0 rows affected (0.00 sec) mysql> insert into bank values ('1003',500) // Query OK, 1 row affected (0.00 sec) -- 记录事务的回滚点 mysql> savepoint a1 // Query OK, 0 rows affected (0.00 sec) mysql> insert into bank values ('1004',200) // Query OK, 1 row affected (0.00 sec) -- 回滚到回滚点 mysql> rollback to a1 // Query OK, 0 rows affected (0.00 sec) -- 查询 mysql> select * from bank // +------+--------+ | card | money | +------+--------+ | 1001 | 900.00 | | 1002 | 101.00 | | 1003 | 500.00 | +------+--------+ 3 rows in set (0.00 sec) 自动提交事务每一个SQL语句都是一个独立的事务小结:1、事务是事务开启的时候开始2、提交事务、回滚事务后事务都结束3、只有innodb支持事务4、一个SQL语句就是一个独立的事务,开启事务是将多个SQL语句放到一个事务中执行1.6 索引1.6.1 概述优点加快查询速度缺点:带索引的表在数据库中需要更多的存储空间 增、删、改命令需要更长的处理时间,因为它们需要对索引进行更新1.6.2 创建索引的指导原则适合创建索引的列1、该列用于频繁搜索 2、该列用于对数据进行排序 3、在WHERE子句中出现的列,在join子句中出现的列。请不要使用下面的列创建索引:1、列中仅包含几个不同的值。 2、表中仅包含几行。为小型表创建索引可能不太划算,因为MySQL在索引中搜索数据所花的时间比在表中逐行搜索所花的时间更长 1.6.3 创建索引1、主键索引:主要创建了主键就会自动的创建主键索引2、唯一索引:创建唯一键就创建了唯一索引-- 创建表的时候添加唯一索引 create table t5( id int primary key, name varchar(20), unique ix_name(name) -- 添加唯一索引 ); -- 给表添加唯一索引 mysql> create table t5( -> name varchar(20), -> addr varchar(50) -> ); Query OK, 0 rows affected (0.00 sec) mysql> create unique index ix_name on t5(name); Query OK, 0 rows affected (0.06 sec) Records: 0 Duplicates: 0 Warnings: 0 -- 通过更改表的方式创建唯一索引 mysql> alter table t5 add unique ix_addr (addr); Query OK, 0 rows affected (0.00 sec) Records: 0 Duplicates: 0 Warnings: 0普通索引-- 创建表的时候添加普通索引 mysql> create table t6( -> id int primary key, -> name varchar(20), -> index ix_name(name) -> ); Query OK, 0 rows affected (0.02 sec) -- 给表添加普通索引 mysql> create table t7( -> name varchar(20), -> addr varchar(50) -> ); Query OK, 0 rows affected (0.00 sec) mysql> create index ix_name on t7(name) ; Query OK, 0 rows affected (0.08 sec) Records: 0 Duplicates: 0 Warnings: 0 -- 通过更改表的方式创建索引 mysql> alter table t7 add index ix_addr(addr); Query OK, 0 rows affected (0.02 sec) Records: 0 Duplicates: 0 Warnings: 0小结:1、创建主键就会创建主键索引2、创建唯一键就会创建唯一索引3、创建唯一键的语法--语法一 create unique [index] 索引名 on 表名(字段名) -- 方法二 alter table 表名 add uniqe [index] 索引名(字段名)4、创建普通索引-- 语法一 create index 索引名 on 表名(字段名) -- 语法二 alter table 表名 add index 索引名(字段名)5、索引创建后,数据库根据查询语句自动选择索引1.6.4 删除索引语法:drop index 索引名 on 表名mysql> drop index ix_name on t7; Query OK, 0 rows affected (0.01 sec) Records: 0 Duplicates: 0 Warnings: 01.7 函数1.7.1 数字类-- 获取随机数 mysql> select rand(); +------------------+ | rand() | +------------------+ | 0.25443412666622 | +------------------+ 1 row in set (0.00 sec) -- 随机排序 mysql> select * from stuinfo order by rand(); -- 随机获取一条记录 mysql> select * from stuinfo order by rand() limit 1; -- 四舍五入,向上取整,向下取整 mysql> select round(3.1415926,3) '四舍五入',truncate(3.14159,3) '截取数据',ceil(3.1) '向上取整',floor(3.9) '向下取整'; +----------+----------+----------+----------+ | 四舍五入 | 截取数据 | 向上取整 | 向下取整 | +----------+----------+----------+----------+ | 3.142 | 3.141 | 4 | 3 | +----------+----------+----------+----------+ 1 row in set (0.04 sec) 注意: 截取数据直接截取,不四舍五入1.7.2 字符串类-- 大小写转换 mysql> select ucase('i name is tom') '转成大写',lcase('My Name IS TOM') '转成小写'; +---------------+----------------+ | 转成大写 | 转成小写 | +---------------+----------------+ | I NAME IS TOM | my name is tom | +---------------+----------------+ 1 row in set (0.00 sec) -- 截取字符串 mysql> select left('abcdef',3) '从左边截取',right('abcdef',3) '从右边截取',substring('abcdef',2,3) '字符串'; +------------+------------+--------+ | 从左边截取 | 从右边截取 | 字符串 | +------------+------------+--------+ | abc | def | bcd | +------------+------------+--------+ 1 row in set (0.00 sec) -- 字符串相连 mysql> select concat('中国','北京','顺义') '地址'; +--------------+ | 地址 | +--------------+ | 中国北京顺义 | +--------------+ 1 row in set (0.00 sec) mysql> select concat(stuname,'-',stusex) 信息 from stuinfo; +-------------+ | 信息 | +-------------+ | 张秋丽-男 | | 李文才-男 | | 李斯文-女 | | 欧阳俊雄-男 | | 诸葛丽丽-女 | | 争青小子-男 | | 梅超风-女 | +-------------+ 7 rows in set (0.00 sec) -- coalesce(str1,str2) :str1有值显示str1,如果str1为空就显示str2 -- 将成绩为空的显示为缺考 mysql> select stuname,coalesce(writtenexam,'缺考'),coalesce(labexam,'缺考') from stuinfo natural left join stumarks; +----------+------------------------------+--------------------------+ | stuname | coalesce(writtenexam,'缺考') | coalesce(labexam,'缺考') | +----------+------------------------------+--------------------------+ | 张秋丽 | 77 | 82 | | 李文才 | 50 | 90 | | 李斯文 | 80 | 58 | | 欧阳俊雄 | 65 | 50 | | 诸葛丽丽 | 缺考 | 缺考 | | 争青小子 | 56 | 48 | | 梅超风 | 缺考 | 缺考 | +----------+------------------------------+--------------------------+ 7 rows in set (0.02 sec) -- length():字节长度,char_length():字符长度 mysql> select length('锄禾日当午') 字节,char_length('锄禾日当午') 字符; +------+------+ | 字节 | 字符 | +------+------+ | 10 | 5 | +------+------+ 1 row in set (0.00 sec)1.7.3 时间类-- 时间戳 mysql> select unix_timestamp(); +------------------+ | unix_timestamp() | +------------------+ | 1560330458 | +------------------+ 1 row in set (0.00 sec) -- 格式化时间戳 mysql> select from_unixtime(unix_timestamp()); +---------------------------------+ | from_unixtime(unix_timestamp()) | +---------------------------------+ | 2019-06-12 17:08:18 | +---------------------------------+ 1 row in set (0.05 sec) -- 获取当前格式化时间 mysql> select now(); +---------------------+ | now() | +---------------------+ | 2019-06-12 17:08:50 | +---------------------+ 1 row in set (0.00 sec) -- 获取年,月,日,小时,分钟,秒 mysql> select year(now()) 年,month(now()) 月,day(now()) 日,hour(now()) 小时,minute(now()) 分钟,second(now())秒; +------+------+------+------+------+------+ | 年 | 月 | 日 | 小时 | 分钟 | 秒 | +------+------+------+------+------+------+ | 2019 | 6 | 12 | 17 | 10 | 48 | +------+------+------+------+------+------+ 1 row in set (0.00 sec) -- 星期,本年第几天; mysql> select dayname(now()) 星期,dayofyear(now()) 本年第几天; +-----------+------------+ | 星期 | 本年第几天 | +-----------+------------+ | Wednesday | 163 | +-----------+------------+ 1 row in set (0.00 sec) -- 日期相减 mysql> select datediff(now(),'2010-08-08') 相距天数; +----------+ | 相距天数 | +----------+ | 3230 | +----------+ 1 row in set (0.00 sec)1.7.4 加密函数1、md5()2、sha()mysql> select md5('aa'); +----------------------------------+ | md5('aa') | +----------------------------------+ | 4124bc0a9335c27f086f24ba207a4912 | +----------------------------------+ 1 row in set (0.00 sec) mysql> select sha('aa'); +------------------------------------------+ | sha('aa') | +------------------------------------------+ | e0c9035898dd52fc65c41454cec9c4d2611bfb37 | +------------------------------------------+ 1 row in set (0.00 sec)1.8 预处理每个代码的段的执行都要经历:词法分析——语法分析——编译——执行预编译一次,可以多次执行。用来解决一条SQL语句频繁执行的问题。预处理语句:prepare 预处理名字 from ‘sql语句’ 执行预处理:execute 预处理名字 [using 变量]例题:不带参数的预处理-- 创建预处理 mysql> prepare stmt from 'select * from stuinfo'; Query OK, 0 rows affected (0.06 sec) Statement prepared -- 执行预处理 mysql> execute stmt; +--------+----------+--------+--------+---------+------------+ | stuNo | stuName | stuSex | stuAge | stuSeat | stuAddress | +--------+----------+--------+--------+---------+------------+ | s25301 | 张秋丽 | 男 | 18 | 1 | 北京 | | s25302 | 李文才 | 男 | 31 | 3 | 上海 | | s25303 | 李斯文 | 女 | 22 | 2 | 北京 | | s25304 | 欧阳俊雄 | 男 | 28 | 4 | 天津 | | s25305 | 诸葛丽丽 | 女 | 23 | 7 | 河南 | | s25318 | 争青小子 | 男 | 26 | 6 | 天津 | | s25319 | 梅超风 | 女 | 23 | 5 | 河北 | +--------+----------+--------+--------+---------+------------+ 7 rows in set (0.00 sec)例题:带一个参数的预处理-- 创建带有位置占位符的预处理语句 mysql> prepare stmt from 'select * from stuinfo where stuno=?' ; Query OK, 0 rows affected (0.00 sec) Statement prepared -- 调用预处理,并传参数 mysql> delimiter // mysql> set @id='s25301'; -> execute stmt using @id // Query OK, 0 rows affected (0.00 sec) +--------+---------+--------+--------+---------+------------+ | stuNo | stuName | stuSex | stuAge | stuSeat | stuAddress | +--------+---------+--------+--------+---------+------------+ | s25301 | 张秋丽 | 男 | 18 | 1 | 北京 | +--------+---------+--------+--------+---------+------------+ 1 row in set (0.00 sec)例题:传递多个参数mysql> prepare stmt from 'select * from stuinfo where stuage>? and stusex=?' // Query OK, 0 rows affected (0.00 sec) Statement prepared mysql> set @age=20; -> set @sex='男'; -> execute stmt using @age,@sex // Query OK, 0 rows affected (0.00 sec) Query OK, 0 rows affected (0.00 sec) +--------+----------+--------+--------+---------+------------+ | stuNo | stuName | stuSex | stuAge | stuSeat | stuAddress | +--------+----------+--------+--------+---------+------------+ | s25302 | 李文才 | 男 | 31 | 3 | 上海 | | s25304 | 欧阳俊雄 | 男 | 28 | 4 | 天津 | | s25318 | 争青小子 | 男 | 26 | 6 | 天津 | +--------+----------+--------+--------+---------+------------+ 3 rows in set (0.00 sec)小结:1、MySQL中变量以@开头2、通过set给变量赋值3、?是位置占位符
-
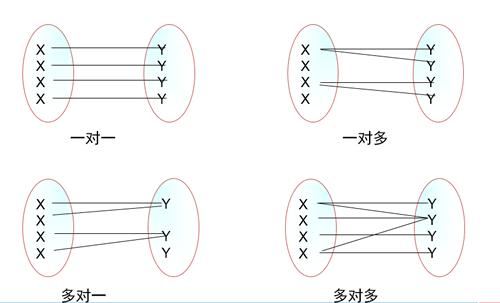
MySQL数据库(三) 1.1 目标掌握一对多关系的数据表设计方案和原理;掌握多对多关系的数据表设计方案和原理;掌握where子句进行数据筛选;掌握group by子句进行数据分类统计;掌握order by子句进行数据排序;了解mysql数据库的设计规范;1.2 实体之间的关系1.2.1 一对多(1:N)主表中的一条记录对应从表中的多条记录实现一对多的方式:主键和非主键建关系问题:说出几个一对多的关系?班主任表——学生表 品牌表——商品表1.2.2 多对一(N:1)多对一就是一对多1.2.3 一对一(1:1)如何实现一对一:主键和主键建关系思考:一对一两个表完全可以用一个表实现,为什么还要分成两个表?答:在字段数量很多情况下,数据量也就很大,每次查询都需要检索大量数据,这样效率低下。我们可以将所有字段分成两个部分,“常用字段”和“不常用字段”,这样对大部分查询者来说效率提高了。【表的垂直分割】1.2.3 多对多(N:M)主表中的一条记录对应从表中的多条记录,从表中的一条记录,对应主表中的多条记录如何实现多对多:利用第三张关系表问题:说出几个多对多的关系?讲师表——学生表 课程表——学生表 商品表——订单表小结:如何实现一对一:主键和主键建关系 如果实现一对多:主键和非主键建关系 如何实现多对多:引入第三张关系表1.3 数据库设计1.3.1 数据库设计的步骤收集信息:与该系统有关人员进行交流、坐谈,充分理解数据库需要完成的任务标识对象(实体-Entity):标识数据库要管理的关键对象或实体标识每个实体的属性(Attribute)标识对象之间的关系(Relationship)将模型转换成数据库规范化1.3.2 例题第一步:收集信息BBS论坛的基本功能: 用户注册和登录,后台数据库需要存放用户的注册信息和在线状态信息; 用户发贴,后台数据库需要存放贴子相关信息,如贴子内容、标题等; 用户可以对发帖进行回复; 论坛版块管理:后台数据库需要存放各个版块信息,如版主、版块名称、贴子数等;第二步:标识对象实体一般是名词: 1、用户对象 2、板块对象 3、帖子对象 4、跟帖对象第三步:标识每个实体的属性第四步:标识对象之间的关系1.3.3 绘制E-R图E-R(Entity-Relationship)实体关系图)完整的E-R图1.3.4 将E-R图转成表实体转成表,属性转成字段如果没有合适的字段做主键,给表添加一个自动增长列做主键。1.4 数据规范化1.4.1 第一范式:确保每列原则性第一范式:的目标是确保每列的原子性,一个字段表示一个含义思考如下表是否满足第一范式思考:地址包含省、市、县、地区是否需要拆分?答:如果仅仅起地址的作用,不需要统计,可以不拆分;如果有按地区统计的功能需要拆分。在实际项目中,建议拆分。1.4.2 第二范式:非键字段必须依赖于键字段第二范式:在满足第一范式的前提下,要求每个表只描述一件事情思考:如下表设计是否合理1.4.3 第三范式:消除传递依赖第三范式:在满足第二范式的前提下,除了主键以外的其他列消除传递依赖。思考:如下表设计是否合理?结论:不满足第三范式,因为语文和数学确定了,总分就确定了1.4.4 反3NF范式越高,数据冗余越少,但是效率有时就越地下,为了提高运行效率,可以适当让数据冗余。学号姓名语文数学总分1李白7788165上面的设计不满足第三范式,但是高考分数表就是这样设计的,为什么?答:高考分数峰值访问量非常大,这时候就是性能更重要。当性能和规范化冲突的时候,我们首选性能。这就是“反三范式”。小结1、第一范式约束的所有字段2、第二范式约束的主键和非主键的关系3、第三范式约束的非主键之间的关系4、范式越高,冗余越少,但表业越多。5、规范化和性能的关系 :性能比规范化更重要1.4.5 例题需求假设某建筑公司要设计一个数据库。公司的业务规 则概括说明如下: 公司承担多个工程项目,每一项工程有:工程号、工程名称、施工人员等 公司有多名职工,每一名职工有:职工号、姓名、性别、职务(工程师、技术员)等 公司按照工时和小时工资率支付工资,小时工资率由职工的职务决定(例如,技术员的小时工资率与工程师不同)标识实体1、工程 2、职工 3、工时 4、小时工资率1.5 查询语句语法:select [选项] 列名 [from 表名] [where 条件] [group by 分组] [order by 排序][having 条件] [limit 限制]1.5.1 字段表达式-- 可以直接输出内容 mysql> select '锄禾日当午'; +------------+ | 锄禾日当午 | +------------+ | 锄禾日当午 | +------------+ 1 row in set (0.00 sec) -- 输出表达式 mysql> select 10*10; +-------+ | 10*10 | +-------+ | 100 | +-------+ 1 row in set (0.00 sec) mysql> select ch,math,ch+math from stu; +------+------+---------+ | ch | math | ch+math | +------+------+---------+ | 80 | NULL | NULL | | 77 | 76 | 153 | | 55 | 82 | 137 | | NULL | 74 | NULL | -- 表达式部分可以用函数 mysql> select rand(); +--------------------+ | rand() | +--------------------+ | 0.6669325378415478 | +--------------------+ 1 row in set (0.00 sec)通过as给字段取别名mysql> select '锄禾日当午' as '标题'; -- 取别名 +------------+ | 标题 | +------------+ | 锄禾日当午 | +------------+ 1 row in set (0.00 sec) mysql> select ch,math,ch+math as '总分' from stu; +------+------+------+ | ch | math | 总分 | +------+------+------+ | 80 | NULL | NULL | | 77 | 76 | 153 | | 55 | 82 | 137 | | NULL | 74 | NULL | -- 多学一招:as可以省略 mysql> select ch,math,ch+math '总分' from stu; +------+------+------+ | ch | math | 总分 | +------+------+------+ | 80 | NULL | NULL | | 77 | 76 | 153 | | 55 | 82 | 137 | | NULL | 74 | NULL |1.5.2 from子句from:来自,from后面跟的是数据源。数据源可以有多个。返回笛卡尔积。插入测试表create table t1( str char(2) ); insert into t1 values ('aa'),('bb'); create table t2( num int ); insert into t2 values (10),(20);测试-- from子句 mysql> select * from t1; +------+ | str | +------+ | aa | | bb | +------+ 2 rows in set (0.00 sec) -- 多个数据源,返回笛卡尔积 mysql> select * from t1,t2; +------+------+ | str | num | +------+------+ | aa | 10 | | bb | 10 | | aa | 20 | | bb | 20 | +------+------+ 4 rows in set (0.00 sec)1.5.3 dual表dual表是一个伪表。在有些特定情况下,没有具体的表的参与,但是为了保证select语句的完整又必须要一个表名,这时候就使用伪表。mysql> select 10*10 as 结果 from dual; +------+ | 结果 | +------+ | 100 | +------+ 1 row in set (0.00 sec)1.5.4 where子句where后面跟的是条件,在数据源中进行筛选。返回条件为真记录MySQL支持的运算符-- 比较运算符 > 大于 < 小于 >= 大于等于 <= 小于等于 = 等于 != 不等于 -- 逻辑运算符 and 与 or 或 not 非 -- 其他 in | not in 字段的值在枚举范围内 between…and|not between…and 字段的值在数字范围内 is null | is not null 字段的值不为空例题:-- 查找语文成绩及格的学生 mysql> select * from stu where ch>=60; -- 查询语文和数学都及格的学生 mysql> select * from stu where ch>=60 and math>=60; -- 查询语文或数学不及格的学生 mysql> select * from stu where ch<60 or math<60;思考:如下语句输出什么?mysql> select * from stu where 1; -- 输出所有数据 mysql> select * from stu where 0; -- 不输出数据思考:如何查找北京和上海的学生-- 通过or实现 mysql> select * from stu where stuaddress='北京' or stuaddress='上海'; -- 通过in语句实现 mysql> select * from stu where stuaddress in ('北京','上海'); -- 查询不是北京和上海的学生 mysql> select * from stu where stuaddress not in ('北京','上海');思考:查找年龄在20~25之间-- 方法一: mysql> select * from stu where stuage>=20 and stuage<=25; -- 方法二: mysql> select * from stu where not(stuage<20 or stuage>25); -- 方法三:between...and... mysql> select * from stu where stuage between 20 and 25; -- 年龄不在20~25之间 mysql> select * from stu where stuage not between 20 and 25;思考:-- 查找缺考的学生 mysql> select * from stu where ch is null or math is null; +--------+----------+--------+--------+---------+------------+------+------+ | stuNo | stuName | stuSex | stuAge | stuSeat | stuAddress | ch | math | +--------+----------+--------+--------+---------+------------+------+------+ | s25301 | 张秋丽 | 男 | 18 | 1 | 北京 | 80 | NULL | | s25304 | 欧阳俊雄 | 男 | 28 | 4 | 天津 | NULL | 74 | +--------+----------+--------+--------+---------+------------+------+------+ -- 查找没有缺考的学生 mysql> select * from stu where ch is not null and math is not null; +--------+----------+--------+--------+---------+------------+------+------+ | stuNo | stuName | stuSex | stuAge | stuSeat | stuAddress | ch | math | +--------+----------+--------+--------+---------+------------+------+------+ | s25302 | 李文才 | 男 | 31 | 3 | 上海 | 77 | 76 | | s25303 | 李斯文 | 女 | 22 | 2 | 北京 | 55 | 82 | | s25305 | 诸葛丽丽 | 女 | 23 | 7 | 河南 | 72 | 56 | | s25318 | 争青小子 | 男 | 26 | 6 | 天津 | 86 | 92 | | s25319 | 梅超风 | 女 | 23 | 5 | 河北 | 74 | 67 | | s25320 | Tom | 男 | 24 | 8 | 北京 | 65 | 67 | | s25321 | Tabm | 女 | 23 | 9 | 河北 | 88 | 77 | +--------+----------+--------+--------+---------+------------+------+------+ 7 rows in set (0.00 sec) -- 查找需要补考的学生 mysql> select * from stu where ch<60 or math<60 or ch is null or math is null; +--------+----------+--------+--------+---------+------------+------+------+ | stuNo | stuName | stuSex | stuAge | stuSeat | stuAddress | ch | math | +--------+----------+--------+--------+---------+------------+------+------+ | s25301 | 张秋丽 | 男 | 18 | 1 | 北京 | 80 | NULL | | s25303 | 李斯文 | 女 | 22 | 2 | 北京 | 55 | 82 | | s25304 | 欧阳俊雄 | 男 | 28 | 4 | 天津 | NULL | 74 | | s25305 | 诸葛丽丽 | 女 | 23 | 7 | 河南 | 72 | 56 | +--------+----------+--------+--------+---------+------------+------+------+ 4 rows in set (0.00 sec)练习:-- 1、查找学号是s25301,s25302,s25303的学生 mysql> select * from stu where stuno in ('s25301','s25302','s25303'); +--------+---------+--------+--------+---------+------------+------+------+ | stuNo | stuName | stuSex | stuAge | stuSeat | stuAddress | ch | math | +--------+---------+--------+--------+---------+------------+------+------+ | s25301 | 张秋丽 | 男 | 18 | 1 | 北京 | 80 | NULL | | s25302 | 李文才 | 男 | 31 | 3 | 上海 | 77 | 76 | | s25303 | 李斯文 | 女 | 22 | 2 | 北京 | 55 | 82 | +--------+---------+--------+--------+---------+------------+------+------+ 3 rows in set (0.00 sec) -- 2、查找年龄是18~20的学生 mysql> select * from stu where stuage between 18 and 20; +--------+---------+--------+--------+---------+------------+------+------+ | stuNo | stuName | stuSex | stuAge | stuSeat | stuAddress | ch | math | +--------+---------+--------+--------+---------+------------+------+------+ | s25301 | 张秋丽 | 男 | 18 | 1 | 北京 | 80 | NULL | +--------+---------+--------+--------+---------+------------+------+------+ 1 row in set (0.00 sec)1.5.5 group by 【分组查询】将查询的结果分组,分组查询目的在于统计数据。-- 查询男生和女生的各自语文平均分 mysql> select stusex,avg(ch) '平均分' from stu group by stusex; +--------+---------+ | stusex | 平均分 | +--------+---------+ | 女 | 72.2500 | | 男 | 77.0000 | +--------+---------+ 2 rows in set (0.00 sec) -- 查询男生和女生各自多少人 mysql> select stusex,count(*) 人数 from stu group by stusex; +--------+------+ | stusex | 人数 | +--------+------+ | 女 | 4 | | 男 | 5 | +--------+------+ 2 rows in set (0.00 sec) -- 查询每个地区多少人 mysql> select stuaddress,count(*) from stu group by stuaddress; +------------+----------+ | stuaddress | count(*) | +------------+----------+ | 上海 | 1 | | 北京 | 3 | | 天津 | 2 | | 河北 | 2 | | 河南 | 1 | +------------+----------+ 5 rows in set (0.00 sec) -- 每个地区的数学平均分 mysql> select stuaddress,avg(math) from stu group by stuaddress; +------------+-----------+ | stuaddress | avg(math) | +------------+-----------+ | 上海 | 76.0000 | | 北京 | 74.5000 | | 天津 | 83.0000 | | 河北 | 72.0000 | | 河南 | 56.0000 | +------------+-----------+ 5 rows in set (0.00 sec)查询字段是普通字段,只取第一个值通过group_concat()函数将同一组的值连接起来显示mysql> select group_concat(stuname),stusex,avg(math) from stu group by stusex; +-------------------------------------+--------+-----------+ | group_concat(stuname) | stusex | avg(math) | +-------------------------------------+--------+-----------+ | 李斯文,诸葛丽丽,梅超风,Tabm | 女 | 70.5000 | | 张秋丽,李文才,欧阳俊雄,争青小子,Tom | 男 | 77.2500 | +-------------------------------------+--------+-----------+ 2 rows in set (0.00 sec)多列分组mysql> select stuaddress,stusex,avg(math) from stu group by stuaddress,stusex; +------------+--------+-----------+ | stuaddress | stusex | avg(math) | +------------+--------+-----------+ | 上海 | 男 | 76.0000 | | 北京 | 女 | 82.0000 | | 北京 | 男 | 67.0000 | | 天津 | 男 | 83.0000 | | 河北 | 女 | 72.0000 | | 河南 | 女 | 56.0000 | +------------+--------+-----------+ 6 rows in set (0.00 sec)小结:1、如果是分组查询,查询字段是分组字段和聚合函数。 2、查询字段是普通字段,只取第一个值 3、group_concat()将同一组的数据连接起来1.5.6 order by排序asc:升序【默认】desc:降序-- 按年龄的升序排列 mysql> select * from stu order by stuage asc; mysql> select * from stu order by stuage; -- 默认是升序 -- 按总分降序 mysql> select *,ch+math '总分' from stu order by ch+math desc;多列排序-- 年龄升序,如果年龄一样,按ch降序排列 mysql> select * from stu order by stuage asc,ch desc;思考如下代码表示什么含义select * from stu order by stuage desc,ch desc; #年龄降序,语文降序 select * from stu order by stuage desc,ch asc; #年龄降序,语文升序 select * from stu order by stuage,ch desc; #年龄升序、语文降序 select * from stu order by stuage,ch; #年龄升序、语文升序1.5.7 having条件having:是在结果集上进行条件筛选例题-- 查询女生 mysql> select * from stu where stusex='女'; +--------+----------+--------+--------+---------+------------+------+------+ | stuNo | stuName | stuSex | stuAge | stuSeat | stuAddress | ch | math | +--------+----------+--------+--------+---------+------------+------+------+ | s25303 | 李斯文 | 女 | 22 | 2 | 北京 | 55 | 82 | | s25305 | 诸葛丽丽 | 女 | 23 | 7 | 河南 | 72 | 56 | | s25319 | 梅超风 | 女 | 23 | 5 | 河北 | 74 | 67 | | s25321 | Tabm | 女 | 23 | 9 | 河北 | 88 | 77 | +--------+----------+--------+--------+---------+------------+------+------+ 4 rows in set (0.00 sec) -- 查询女生 mysql> select * from stu having stusex='女'; +--------+----------+--------+--------+---------+------------+------+------+ | stuNo | stuName | stuSex | stuAge | stuSeat | stuAddress | ch | math | +--------+----------+--------+--------+---------+------------+------+------+ | s25303 | 李斯文 | 女 | 22 | 2 | 北京 | 55 | 82 | | s25305 | 诸葛丽丽 | 女 | 23 | 7 | 河南 | 72 | 56 | | s25319 | 梅超风 | 女 | 23 | 5 | 河北 | 74 | 67 | | s25321 | Tabm | 女 | 23 | 9 | 河北 | 88 | 77 | +--------+----------+--------+--------+---------+------------+------+------+ 4 rows in set (0.00 sec) -- 查询女生姓名 mysql> select stuname from stu where stusex='女'; +----------+ | stuname | +----------+ | 李斯文 | | 诸葛丽丽 | | 梅超风 | | Tabm | +----------+ 4 rows in set (0.00 sec) -- 使用having报错,因为结果集中没有stusex字段 mysql> select stuname from stu having stusex='女'; ERROR 1054 (42S22): Unknown column 'stusex' in 'having clause'小结:having和where的区别:where是对原始数据进行筛选,having是对记录集进行筛选。1.5.8 limit语法:limit [起始位置],显示长度-- 从第0个位置开始取,取3条记录 mysql> select * from stu limit 0,3; -- 从第2个位置开始取,取3条记录 mysql> select * from stu limit 2,3; +--------+----------+--------+--------+---------+------------+------+------+ | stuNo | stuName | stuSex | stuAge | stuSeat | stuAddress | ch | math | +--------+----------+--------+--------+---------+------------+------+------+ | s25303 | 李斯文 | 女 | 22 | 2 | 北京 | 55 | 82 | | s25304 | 欧阳俊雄 | 男 | 28 | 4 | 天津 | NULL | 74 | | s25305 | 诸葛丽丽 | 女 | 23 | 7 | 河南 | 72 | 56 | +--------+----------+--------+--------+---------+------------+------+------+ 3 rows in set (0.00 sec)起始位置可以省略,默认是从0开始mysql> select * from stu limit 3; +--------+---------+--------+--------+---------+------------+------+------+ | stuNo | stuName | stuSex | stuAge | stuSeat | stuAddress | ch | math | +--------+---------+--------+--------+---------+------------+------+------+ | s25301 | 张秋丽 | 男 | 18 | 1 | 北京 | 80 | NULL | | s25302 | 李文才 | 男 | 31 | 3 | 上海 | 77 | 76 | | s25303 | 李斯文 | 女 | 22 | 2 | 北京 | 55 | 82 | +--------+---------+--------+--------+---------+------------+------+------+ 3 rows in set (0.00 sec)例题:找出班级总分前三名mysql> select *,ch+math total from stu order by (ch+math) desc limit 0,3; +--------+----------+--------+--------+---------+------------+------+------+-------+ | stuNo | stuName | stuSex | stuAge | stuSeat | stuAddress | ch | math | total | +--------+----------+--------+--------+---------+------------+------+------+-------+ | s25318 | 争青小子 | 男 | 26 | 6 | 天津 | 86 | 92 | 178 | | s25321 | Tabm | 女 | 23 | 9 | 河北 | 88 | 77 | 165 | | s25302 | 李文才 | 男 | 31 | 3 | 上海 | 77 | 76 | 153 | +--------+----------+--------+--------+---------+------------+------+------+-------+ 3 rows in set (0.00 sec)多学一招:limit在update和delete语句中也是可以使用的。-- 前3名语文成绩加1分 mysql> update stu set ch=ch+1 order by ch+math desc limit 3; Query OK, 3 rows affected (0.00 sec) Rows matched: 3 Changed: 3 Warnings: 0 -- 前3名删除 mysql> delete from stu order by ch+math desc limit 3; Query OK, 3 rows affected (0.00 sec)1.5.9 查询语句中的选项查询语句中的选项有两个:1、 all:显示所有数据 【默认】2、 distinct:去除结果集中重复的数据mysql> select all stuaddress from stu; +------------+ | stuaddress | +------------+ | 北京 | | 北京 | | 天津 | | 河南 | | 河北 | | 北京 | +------------+ 6 rows in set (0.00 sec) -- 去除重复的项 mysql> select distinct stuaddress from stu; +------------+ | stuaddress | +------------+ | 北京 | | 天津 | | 河南 | | 河北 | +------------+ 4 rows in set (0.00 sec)1.6 聚合函数sum() 求和avg() 求平均值max() 求最大值min() 求最小值count() 求记录数# 语文最高分 mysql> select max(ch) '语文最大值' from stu; +------------+ | 语文最大值 | +------------+ | 88 | +------------+ 1 row in set (0.00 sec) #求语文总分、语文平均分、语文最低分、总人数 mysql> select max(ch) 语文最高分,min(ch) 语文最低分,sum(ch) 语文总分,avg(ch) 语文平均分,count(*) 总人数 from stu; +------------+------------+----------+------------+--------+ | 语文最高分 | 语文最低分 | 语文总分 | 语文平均分 | 总人数 | +------------+------------+----------+------------+--------+ | 88 | 55 | 597 | 74.6250 | 9 | +------------+------------+----------+------------+--------+ 1 row in set (0.00 sec)1.7 模糊查询1.7.1 通配符_ [下划线] 表示任意一个字符% 表示任意字符练习1、满足“T_m”的有(A、C) A:Tom B:Toom C:Tam D:Tm E:Tmo 2、满足“T_m_”的有( B C) A:Tmom B:Tmmm C:T1m2 D:Tmm E:Tm 3、满足“张%”的是(ABCD) A:张三 B:张三丰 C:张牙舞爪 D:张 E:小张 4、满足“%诺基亚%”的是(ABCD) A:诺基亚2100 B:2100诺基亚 C:把我的诺基亚拿过来 D:诺基亚1.7.2 模糊查询(like)模糊查询的条件不能用'=',要使用like。mysql> select * from stu where stuname like 'T_m'; +--------+---------+--------+--------+---------+------------+------+------+ | stuNo | stuName | stuSex | stuAge | stuSeat | stuAddress | ch | math | +--------+---------+--------+--------+---------+------------+------+------+ | s25320 | Tom | 男 | 24 | 8 | 北京 | 65 | 67 | +--------+---------+--------+--------+---------+------------+------+------+ 1 row in set (0.00 sec) -- 查询姓张的学生 mysql> select * from stu where stuname like '张%'; +--------+---------+--------+--------+---------+------------+------+------+ | stuNo | stuName | stuSex | stuAge | stuSeat | stuAddress | ch | math | +--------+---------+--------+--------+---------+------------+------+------+ | s25301 | 张秋丽 | 男 | 18 | 1 | 北京 | 80 | NULL | +--------+---------+--------+--------+---------+------------+------+------+ 1 row in set (0.00 sec)1.8 union(联合)插入测试数据create table emp( id tinyint unsigned auto_increment primary key, name varchar(20) not null, skill set('PHP','mysql','java') ); insert into emp values (null,'李白',1),(null,'杜甫',2),(null,'白居易',4) insert into emp values (null,'争青小子',3)1.8.1 union的使用作用:将多个select语句结果集纵向联合起来语法:select 语句 union [选项] select 语句 union [选项] select 语句-- 查询stu表中的姓名和emp表中姓名 结果自动合并的重复的记录 mysql> select stuname from stu union select name from emp;例题:查询上海的男生和北京的女生-- 方法一: mysql> select * from stu where (stuaddress='上海' and stusex='男') or (stuaddress='北京' and stusex='女'); +--------+---------+--------+--------+---------+------------+------+------+ | stuNo | stuName | stuSex | stuAge | stuSeat | stuAddress | ch | math | +--------+---------+--------+--------+---------+------------+------+------+ | s25302 | 李文才 | 男 | 31 | 3 | 上海 | 77 | 76 | | s25303 | 李斯文 | 女 | 22 | 2 | 北京 | 55 | 82 | +--------+---------+--------+--------+---------+------------+------+------+ 2 rows in set (0.00 sec) -- 方法二:union mysql> select * from stu where stuaddress='上海' and stusex='男' union select * from stu where stuaddress='北京' and stusex='女'; +--------+---------+--------+--------+---------+------------+------+------+ | stuNo | stuName | stuSex | stuAge | stuSeat | stuAddress | ch | math | +--------+---------+--------+--------+---------+------------+------+------+ | s25302 | 李文才 | 男 | 31 | 3 | 上海 | 77 | 76 | | s25303 | 李斯文 | 女 | 22 | 2 | 北京 | 55 | 82 | +--------+---------+--------+--------+---------+------------+------+------+ 2 rows in set (0.00 sec) 结论:union可以将一个复杂的条件转成两个简单的条件1.8.2 union的选项union的选项有两个1、 all:显示所有数据2、 distinct:去除重复的数据【默认】mysql> select stuname from stu union all select name from emp;1.8.3 union的注意事项1、 union两边的select语句的字段个数必须一致2、 union两边的select语句的字段名可以不一致,最终按第一个select语句的字段名。3、 union两边的select语句中的数据类型可以不一致。1.9 补充1.9.1 插入数据时主键冲突-- 插入测试表 mysql> create table stu( -> id char(4) primary key, -> name varchar(20) -> )engine=innodb; Query OK, 0 rows affected (0.06 sec) -- 插入测试数据 mysql> insert into stu values ('s001','tom'); Query OK, 1 row affected (0.00 sec)如果插入的主键重复会报错解决方法:如果插入的主键重复就执行替换语法一:mysql> replace into stu values('s002','ketty'); Query OK, 2 rows affected (0.00 sec) # 原理:如果插入的主键不重复就直接插入,如果主键重复就替换(删除原来的记录,插入新记录)语法二(推荐):on duplicate key update # 当插入的值与主键或唯一键有冲突执行update操作 -- 例题 mysql> insert into stu values ('s002','李白') on duplicate key update name='李白'; Query OK, 2 rows affected (0.00 sec) # 插入的数据和主键或唯一键起冲突,将s002的name字段改为‘李白’
-
MySQL数据库(二) 1.1 目标掌握char和varchar的应用;了解text类型是用来存储长文本数据;了解字段属性的作用;掌握主键primary key的应用以及效果;掌握逻辑主键的自增长auto_increment应用;掌握唯一键与主键的区别;了解外键的约束作用;掌握主键冲突的两种解决方案;1.2 数据类型MySQL中的数据类型是强类型1.2.1 数值型1、 整型整形占用字节数范围tinyint1-128~127smallint2-32768~32767mediumint3-8388608~8388607int4-2147483648~2147483647bigint8-9223372036854775808~9223372036854775807选择的范围尽可能小,范围越小占用资源越少mysql> create table stu1( -> id tinyint, # 范围要尽可能小,范围越小,占用空间越少 -> name varchar(20) -> ); Query OK, 0 rows affected (0.02 sec) -- 超出范围会报错 mysql> insert into stu1 values (128,'tom'); ERROR 1264 (22003): Out of range value for column 'id' at row 1无符号整形(unsigned) 无符号整形就是没有负数,无符号整数是整数的两倍mysql> create table stu2( -> id tinyint unsigned # 无符号整数 -> ); Query OK, 0 rows affected (0.02 sec) mysql> insert into stu2 values (128); Query OK, 1 row affected (0.00 sec)整形支持显示宽度,显示宽带是最小的显示位数,如int(11)表示整形最少用11位表示,如果不够位数用0填充。显示宽度默认不起作用,必须结合zerofill才起作用。mysql> create table stu4( -> id int(5), -> num int(5) zerofill # 添加前导0,int(5)显示宽带是5 -> ); Query OK, 0 rows affected (0.05 sec) mysql> insert into stu4 values (12,12); Query OK, 1 row affected (0.00 sec) mysql> select * from stu4; +------+-------+ | id | num | +------+-------+ | 12 | 00012 | +------+-------+ 1 row in set (0.00 sec)小结:1、范围要尽可能小,范围越小,占用空间越少 2、无符号整数是整数的两倍 3、整形支持显示宽度,显示宽带是最小的显示位数,必须结合zerofill才起作用2、浮点型浮点型占用字节数范围float(单精度型)4-3.4E+38~3.4E+38double(双精度型)8-1.8E+308~1.8E+308浮点型的声明:float(M,D) double(M,D) M:总位数 D:小数位数例题mysql> create table stu5( -> num1 float(5,2), -- 浮点数 -> num2 double(6,1) -- 双精度数 -> ); Query OK, 0 rows affected (0.05 sec) mysql> insert into stu5 values (3.1415,12.96); Query OK, 1 row affected (0.00 sec) mysql> select * from stu5; +------+------+ | num1 | num2 | +------+------+ | 3.14 | 13.0 | +------+------+ 1 row in set (0.00 sec)MySQL浮点数支持科学计数法mysql> create table stu6( -> num float # 不指定位数,默认是小数点后面6位 double默认是17位 -> ); Query OK, 0 rows affected (0.03 sec) mysql> insert into stu6 values (5E2),(6E-2); # 插入科学计数法 Query OK, 2 rows affected (0.00 sec) Records: 2 Duplicates: 0 Warnings: 0 mysql> select * from stu6; +------+ | num | +------+ | 500 | | 0.06 | +------+ 2 rows in set (0.00 sec)浮点数精度会丢失mysql> insert into stu6 values(99.999999999); Query OK, 1 row affected (0.00 sec) mysql> select * from stu6; +------+ | num | +------+ | 100 | +------+小结:1、浮点数有单精度和双精度 2、浮点数支持科学计数法 3、浮点数精度会丢失3、小数(定点数)原理:将整数部分和小数部分分开存储语法:decimal(M,D)例题:mysql> create table stu8( -> num decimal(20,9) # 存放定点数 -> ); Query OK, 0 rows affected (0.00 sec) mysql> insert into stu8 values(12.999999999); Query OK, 1 row affected (0.00 sec) mysql> select * from stu8; +--------------+ | num | +--------------+ | 12.999999999 | +--------------+ 1 row in set (0.00 sec)小结:1、decimal是变长的,大致是每9个数字用4个字节存储,整数和小数分开计算。M最大是65,D最大是30,默认是(10,2)。 2、定点和浮点都支持无符号、显示宽度0填充。1.2.2 字符型在数据库中没有字符串概念,只有字符,所以数据库中只能用单引号数据类型描述char定长字符,最大可以到255varchar可变长度字符,最大可以到65535tinytext2^8^–1 =255text2^16^–1 =65535mediumtext2^24^–1longtext2^32^–1char(4):存放4个字符,中英文一样。varchar(L)实现变长机制,需要额外的空间来记录数据真实的长度。L的理论长度是65535,但事实上达不到,因为有的字符是多字节字符,所以L达不到65535。text系列的类型在表中存储的是地址,占用大小大约10个字节一个记录的所有字段的总长度也不能超过65535个字节。小结:1、char是定长,var是变长 2、char最大值是255,varchar最大值是65535,具体要看字符编码 3、text系列在表中存储的是地址 4、一条记录的总长度不能超过655351.2.3 枚举(enum)从集合中选择一个值作为数据(单选)mysql> create table stu12( -> name varchar(20), -> sex enum('男','女','保密') # 枚举 -> ); Query OK, 0 rows affected (0.06 sec) -- 插入的枚举值只能是枚举中提供的选项 mysql> insert into stu12 values ('tom','男'); Query OK, 1 row affected (0.00 sec) -- 报错,只能插入男、女、保密 mysql> insert into stu12 values ('tom','不告诉你'); ERROR 1265 (01000): Data truncated for column 'sex' at row 1枚举值是通过整形数字来管理的,第一个值是1,第二个值是2,以此类推,枚举值在数据库存储的是整形数字。mysql> insert into stu12 values ('berry',2); -- 插入数字 Query OK, 1 row affected (0.00 sec) mysql> select * from stu12; +-------+------+ | name | sex | +-------+------+ | tom | 男 | | berry | 女 | +-------+------+ mysql> select * from stu12 where sex=2; -- 2表示第二个枚举值 +-------+------+ | name | sex | +-------+------+ | berry | 女 | +-------+------+ 1 row in set (0.00 sec)枚举优点:(1)、限制值 (2)、节省空间 (3)、运行速度快(整形比字符串运行速度快)思考:已知枚举占用两个字节,所以最多可以有多少个枚举值?答:2字节=16位,2^16^=65536,范围是(0-65535),由于枚举从1开始,所以枚举值最多有65535个1.2.4 集合(set)从集合中选择一些值作为数据(多选)mysql> create table stu13( -> name varchar(20), -> hobby set('爬山','读书','游泳','烫头') -- 集合 -> ); Query OK, 0 rows affected (0.00 sec) mysql> insert into stu13 values ('tom','爬山'); mysql> insert into stu13 values ('Berry','爬山,游泳'); Query OK, 1 row affected (0.00 sec) mysql> insert into stu13 values ('Berry','游泳,爬山'); -- 插入的顺序不一样,但显示的顺序一样 Query OK, 1 row affected (0.00 sec) mysql> select * from stu13; +-------+-----------+ | name | hobby | +-------+-----------+ | tom | 爬山 | | Berry | 爬山,游泳 | | Berry | 爬山,游泳 | +-------+-----------+ 3 rows in set (0.00 sec)集合和枚举一样,也为每个集合元素分配一个固定值,分配方式是从前往后按2的0、1、2、…次方,转换成二进制后只有一位是1,其他都是0。'爬山','读书','游泳','烫头' 1 2 4 8 mysql> select hobby+0 from stu13; +---------+ | hobby+0 | +---------+ | 1 | | 5 | | 5 | +---------+ mysql> insert into stu13 values ('rose',15); Query OK, 1 row affected (0.00 sec)已知集合类型占8个字节,那么集合中最多有多少选项答:有64个选项。1.2.5 日期时间型数据类型描述datetime日期时间,占用8个字节date日期 占用3个字节time时间 占用3个字节year年份,占用1个字节timestamp时间戳,占用4个字节1、datetime和datedatetime格式:年-月-日 小时:分钟:秒。支持的范围是'1000-01-01 00:00:00'到'9999-12-3123:59:59'。mysql> create table stu14( -> t1 datetime, -- 日期时间 -> t2 date -- 日期 -> ); Query OK, 0 rows affected (0.05 sec) -- 插入测试数据 mysql> insert into stu14 values ('2019-01-15 12:12:12','2019-01-15 12:12:12'); Query OK, 1 row affected, 1 warning (0.00 sec) -- 查询 mysql> select * from stu14; +---------------------+------------+ | t1 | t2 | +---------------------+------------+ | 2019-01-15 12:12:12 | 2019-01-15 | +---------------------+------------+ 1 row in set (0.00 sec)2、timestamp(时间戳)datetime类型和timestamp类型表现上是一样的,他们的区别在于:datetime从1000到9999,而timestamp从1970年~2038年(原因在于timestamp占用4个字节,和整形的范围一样,2038年01月19日11:14:07以后的秒数就超过了4个字节的长度)mysql> create table stu15( -> t1 timestamp -> ); Query OK, 0 rows affected (0.06 sec) mysql> insert into stu15 values ('2038-01-19 11:14:07'); Query OK, 1 row affected (0.00 sec)3、year只能表示1901~2155之间的年份,因为只占用1个字节,只能表示255个数mysql> create table stu16( -> y1 year -> ); Query OK, 0 rows affected (0.08 sec) mysql> insert into stu16 values (2155); Query OK, 1 row affected (0.00 sec)4、time可以表示时间,也可以表示时间间隔。范围是:-838:59:59~838:59:59mysql> create table stu17( -> t1 time -> ); Query OK, 0 rows affected (0.02 sec) mysql> insert into stu17 values ('12:12:12'); Query OK, 1 row affected (0.00 sec) mysql> insert into stu17 values ('212:12:12'); Query OK, 1 row affected (0.00 sec) mysql> insert into stu17 values ('-212:12:12'); Query OK, 1 row affected (0.00 sec) mysql> insert into stu17 values ('839:00:00'); -- 报错 ERROR 1292 (22007): Incorrect time value: '839:00:00' for column 't1' at row 1 -- time支持以天的方式来表示时间间隔 mysql> insert into stu17 values ('10 10:25:25'); -- 10天10小时25分25秒 Query OK, 1 row affected (0.00 sec) mysql> select * from stu17; +------------+ | t1 | +------------+ | 12:12:12 | | 212:12:12 | | -212:12:12 | | 250:25:25 | +------------+ 4 rows in set (0.00 sec)1.2.6 BooleanMySQL不支持布尔型,true和false在数据库中对应的是1和0mysql> create table stu18( -> flag boolean -> ); Query OK, 0 rows affected (0.05 sec) mysql> desc stu18; +-------+------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+------------+------+-----+---------+-------+ | flag | tinyint(1) | YES | | NULL | | +-------+------------+------+-----+---------+-------+ 1 row in set (0.00 sec) mysql> insert into stu18 values (true),(false); Query OK, 2 rows affected (0.00 sec) Records: 2 Duplicates: 0 Warnings: 0 mysql> select * from stu18; +------+ | flag | +------+ | 1 | | 0 | +------+ 2 rows in set (0.00 sec小结:boolean型在MySQL中对应的是tinyint。1.2.6 练习题电话号码一般使用什么数据类型存储? varchar 手机号码用什么数据类型 char 性别一般使用什么数据类型存储? char tinyint enum 年龄信息一般使用什么数据类型存储? tinyint 照片信息一般使用什么数据类型存储? binary 薪水一般使用什么数据类型存储? decimal1.3 列属性1.3.1 是否为空(null|not null)null表示字段值可以为null not null字段值不能为空练习学员姓名允许为空吗? not null 家庭地址允许为空吗? not null 电子邮件信息允许为空吗? null 考试成绩允许为空吗? null1.3.2 默认值(default)如果一个字段没有插入值,可以默认插入一个指定的值mysql> create table stu19( -> name varchar(20) not null default '姓名不详', -> addr varchar(50) not null default '地址不详' -> ); Query OK, 0 rows affected (0.05 sec) mysql> insert into stu19(name) values ('tom'); Query OK, 1 row affected (0.00 sec) mysql> insert into stu19 values (default,default); Query OK, 1 row affected (0.00 sec) mysql> select * from stu19; +----------+----------+ | name | addr | +----------+----------+ | tom | 地址不详 | | 姓名不详 | 地址不详 | +----------+----------+ 2 rows in set (0.00 sec)小结:default关键字用来插入默认值1.3.3 自动增长(auto_increment)字段值从1开始,每次递增1,自动增长的值就不会有重复,适合用来生成唯一的id。在MySQL中只要是自动增长列必须是主键1.3.4 主键(primary key)主键概念:唯一标识表中的记录的一个或一组列称为主键。特点:1、不能重复、不能为空 2、一个表只能有一个主键。作用:1、保证数据完整性 2、加快查询速度选择主键的原则最少性:尽量选择单个键作为主键 稳定性:尽量选择数值更新少的列作为主键 比如:学号,姓名、地址 这三个字段都不重复,选哪个做主键 选学号,因为学号最稳定练习-- 创建主键方法一 mysql> create table stu20( -> id int auto_increment primary key, -> name varchar(20) -> ); Query OK, 0 rows affected (0.04 sec) -- 创建主键方法二 mysql> create table stu21( -> id int auto_increment, -> name varchar(20), -> primary key(id) -> ); Query OK, 0 rows affected (0.02 sec)组合键mysql> create table stu22( -> classname varchar(20), -> stuname varchar(20), -> primary key(classname,stuname) -- 创建组合键 -> ); Query OK, 0 rows affected (0.00 sec) mysql> desc stu22; +-----------+-------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-----------+-------------+------+-----+---------+-------+ | classname | varchar(20) | NO | PRI | | | | stuname | varchar(20) | NO | PRI | | | +-----------+-------------+------+-----+---------+-------+ 2 rows in set (0.00 sec)通过更改表添加主键mysql> create table stu23( -> id int, -> name varchar(20) -> ); Query OK, 0 rows affected (0.05 sec) -- 添加主键 mysql> alter table stu23 add primary key(id); Query OK, 0 rows affected (0.09 sec) Records: 0 Duplicates: 0 Warnings: 0删除主键mysql> alter table stu23 drop primary key; Query OK, 0 rows affected (0.03 sec) Records: 0 Duplicates: 0 Warnings: 0插入数据mysql> create table stu25( -> id tinyint unsigned auto_increment primary key, -> name varchar(20) -> ); Query OK, 0 rows affected (0.05 sec) -- 插入数据 mysql> insert into stu25 values (3,'tom'); -- 可以直接插入数字 Query OK, 1 row affected (0.06 sec) -- 自动增长列可以插入null,让列的值自动递增 mysql> insert into stu25 values (null,'berry'); Query OK, 1 row affected (0.00 sec)小结:1、只要是auto_increment必须是主键,但是主键不一定是auto_increment2、主键特点是不能重复不能为空3、一个表只能有一个主键,但是一个主键可以有多个字段组成4、自动增长列通过插入null值让其递增5、自动增长列的数据被删除,默认不再重复使用。truncate table删除数据后,再次插入从1开始练习在主键列输入的数值,允许为空吗? 不可以 一个表可以有多个主键吗? 不可以 在一个学校数据库中,如果一个学校内允许重名的学员,但是一个班级内不允许学员重名,可以组合班级和姓名两个字段一起来作为主键吗? 对 标识列(自动增长列)允许为字符数据类型吗? 不允许 一个自动增长列中,插入3行,删除2行,插入3行,删除2行,插入3行,删除2行,再次插入是多少? 101.3.5 唯一键(unique)键区别主键1、不能重复,不能为空2、一个表只能有一个主键唯一键1、不能重刻,可以为空2、一个表可以有多个唯一键例题-- 创建表的时候创建唯一键 mysql> create table stu26( -> id int auto_increment primary key, -> name varchar(20) unique -- 唯一键 -> ); Query OK, 0 rows affected (0.05 sec) -- 方法二 mysql> create table stu27( -> id int primary key, -> name varchar(20), -> unique(name) -> ); Query OK, 0 rows affected (0.05 sec) 多学一招: unique 或 unique key 是一样的通过修改表添加唯一键-- 将name设为唯一键 mysql> alter table stu28 add unique(name); -- 将name,addr设为唯一键 mysql> alter table stu28 add unique(name),add unique(addr); Query OK, 0 rows affected (0.00 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> desc stu28; +-------+-------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+-------------+------+-----+---------+-------+ | id | int(11) | NO | PRI | NULL | | | name | varchar(20) | YES | UNI | NULL | | | addr | varchar(20) | YES | UNI | NULL | | +-------+-------------+------+-----+---------+-------+ 3 rows in set (0.02 sec)通过show create table 查看唯一键的名字通过唯一键的名字删除唯一键mysql> alter table stu28 drop index name; Query OK, 0 rows affected (0.00 sec) Records: 0 Duplicates: 0 Warnings: 01.3.6 备注(comment)说明性文本mysql> create table stu29( -> id int primary key comment '学号', -> name varchar(20) not null comment '姓名' -> ); Query OK, 0 rows affected (0.03 sec)注意:备注属于SQL代码的一部分1.4 SQL注释单行注释-- 单行注释 # 单行注释 多行注释 /* */1.5 数据完整性1.5.1 数据完整性包括1、实体完整性1、主键约束 2、唯一约束 3、标识列2、 域完整性1、数据类型约束 2、非空约束 3、默认值约束3、 引用完整性外键约束4、 自定义完整性1、存储过程 2、触发器1.5.2 主表和从表主表中没有的记录,从表不允许插入从表中有的记录,主表中不允许删除删除主表前,先删子表1.5.3 外键(foreign key)外键:从表中的公共字段-- 创建表的时候添加外键 drop table if exists stuinfo; create table stuinfo( id tinyint primary key, name varchar(20) )engine=innodb; drop table if exists stuscore; create table stuscore( sid tinyint primary key, score tinyint unsigned, foreign key(sid) references stuinfo(id) -- 创建外键 )engine=innodb; -- 通过修改表的时候添加外键 语法:alter table 从表 add foreign key(公共字段) references 主表(公共字段) drop table if exists stuinfo; create table stuinfo( id tinyint primary key, name varchar(20) )engine=innodb; drop table if exists stuscore; create table stuscore( sid tinyint primary key, score tinyint unsigned )engine=innodb; alter table stuscore add foreign key (sid) references stuinfo(id)删除外键通过外键的名字删除外键-- 删除外键 mysql> alter table stuscore drop foreign key `stuscore_ibfk_1`; Query OK, 0 rows affected (0.00 sec) Records: 0 Duplicates: 0 Warnings: 0小结:1、只有innodb才能支持外键 2、公共字段的名字可以不一样,但是数据类型要一样1.5.4 三种外键操作1、 严格限制(参见主表和从表)2、 置空操作(set null):如果主表记录删除,或关联字段更新,则从表外键字段被设置为null。3、 级联操作(cascade):如果主表记录删除,则从表记录也被删除。主表更新,从表外键字段也更新。语法:foreign key (外键字段) references 主表名 (关联字段) [主表记录删除时的动作] [主表记录更新时的动作]。一般说删除时置空,更新时级联。drop table if exists stuinfo; create table stuinfo( id tinyint primary key comment '学号,主键', name varchar(20) comment '姓名' )engine=innodb; drop table if exists stuscore; create table stuscore( id int auto_increment primary key comment '主键', sid tinyint comment '学号,外键', score tinyint unsigned comment '成绩', foreign key(sid) references stuinfo(id) on delete set null on update cascade )engine=innodb;小结:置空、级联操作中外键不能是从表的主键1.6 补充phpstudy中MySQL默认不是严格模式,将MySQL设置成严格模式打开my.ini,在sql-mode的值中,添加STRICT_TRANS_TABLESsql-mode="NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES"测试单词medium:中等的 small:小 tiny:微小 big:大
-
MySQL数据库(一) 1.1 目标掌握数据库的作用;能够通俗的解释什么是关系型数据库;能够至少说出三种关系型数据库;掌握MySQL客户端登录和登出MySQL服务器;理解数据库具体数据的存储逻辑;掌握创建、查看和删除数据库;了解MySQL数据库创建与删除指令对应的文件效果掌握数据表的增删改查操作;掌握数据的增删改查操作;1.2 数据库介绍1.2.1 作用数据库是用来存放数据的仓库数据库中存放的是表,表中存放的是数据。1.2.2 数据库的发展史萌芽阶段:文件系统最初始的数据库是用磁盘来存储数据的。文件就是最早的数据库。第一代数据库:层次模型优点:这是导航结构优点:结构清晰,分类查询方便缺点:有可能造成数据无效第一代数据库:网状模型网状模型解决了层次模型的数据不一致的问题,但没有解决导航问题。导航结构在查询中有时候效率低下,比如查询整个公司的四月的营业额。第二阶段:关系模型特点:1、每个表都是独立的2、通过关系字段将两个表连接起来3、关系:两个表的公共字段4、关系型数据库中多表联合查询效率低下。多学一招:为了解决关系型数据库多表查询效率的问题,项目中使用了NoSQL(非关系型数据库,Redis、mongodb等等),在数据库中按照键值对来存储,它是关系型数据库的补充。1.2.3 SQLStructured Query Language(结构化查询语言),是用来操作关系型数据库的一门语言。这是一个关系型数据库的通用操作语言,也成为标准SQL,也叫SQL-92。脚下留心:数据库的生产厂商为了占有市场份额,都会在标准SQL的基础上扩展一些自己的东西以吸引用户。1.2.4 常用的关系型数据库关系型数据库开发公司使用语言access微软公司SQLSQL Server微软公司T-SQLOracle甲骨文公司PL/SQLMySQL被甲骨文公司收购MySQL思考:已知标准SQL可以在所有的关系型数据库上运行,在Oracle上编写的PL/SQL能否在MySQL上运行?答:不可以,只能运行标准SQL1.3 连接服务器数据库是CS模式的软件,所以要连接数据库必须要有客户端软件。MySQL数据库默认端口号是33061.3.1 window界面连接服务器1、Navicat2、MySQL-Front1.3.2 通过web窗体连接主要有浏览器就可以访问数据库1.3.3 命令行连接host -h 主机 port -P 端口号 (大写) user -u 用户名 password -p 密码 (小写)例题-- 连接数据库 F:\wamp\PHPTutorial\MySQL\bin>mysql -h127.0.0.1 -P3306 -uroot -proot -- 明文 -- 如果连接本地数据库 -h可以省略 如果服务器端口是3306,-P端口号也可以省略 F:\wamp\PHPTutorial\MySQL\bin>mysql -uroot -proot -- 明文 -- 密文 F:\wamp\PHPTutorial\MySQL\bin>mysql -uroot -p Enter password: ****1.3.4 退出登录mysql> exit -- 方法一 mysql> quit -- 方法二 mysql> \q -- 方法三1.4 数据库基本概念1.4.1 数据库、表相关数据库:数据库中存放的是表,一个数据库中可以存放多个表表:表是用来存放数据的。关系:两个表的公共字段行:也称记录,也称实体列:也称字段,也称属性脚下留心:就表结构而言,表分为行和列;就表数据而言,表分为记录和字段;就面向对象而言,一个记录就是一个实体,一个字段就是一个属性。1.4.2 数据相关1、数据冗余:相同的数据存储在不同的地方冗余只能减少,不能杜绝。 减少冗余的方法是分表2、数据完整性:正确性+准确性=数据完整性正确性:数据类型正确 准确性:数据范围要准确思考:学生的年龄是整型,输入1000岁,正确性和准确性如何?答:正确的,但不准确。失去了数据完整性。1.4.3 数据库执行过程1.5 数据库的操作1.5.1 创建数据库语法:create database [if not exists] 数据名 [选项]例题-- 创建数据库 mysql> create database stu; Query OK, 1 row affected (0.06 sec) -- 创建数据库时,如果数据库已经存在就要报错 mysql> create database stu; # ERROR 1007 (HY000): Can't create database 'stu'; database exists -- 在创建数据库时候,判断数据库是否存在,不存在就创建 mysql> create database if not exists stu; Query OK, 1 row affected, 1 warning (0.00 sec) -- 特殊字符、关键字做数据库名,使用反引号将数据库名括起来 mysql> create database `create`; Query OK, 1 row affected (0.04 sec) mysql> create database `%$`; Query OK, 1 row affected (0.05 sec) -- 创建数据库时指定存储的字符编码 mysql> create database emp charset=gbk; Query OK, 1 row affected (0.00 sec) # 如果不指定编码,数据库默认使用安装数据库时指定的编码MySQL数据库的目录数据库保存的路径在安装MySQL的时候就配置好。 也可以在my.ini配置文件中更改数据库的保存地址。(datadir="F:/wamp/PHPTutorial/MySQL/data/") 一个数据库就对应一个文件夹,在文件夹中有一个db.opt文件。在此文件中设置数据库的字符集和校对集**小结:1、如果创建的数据库已存在,就会报错。解决方法:创建数据库的时候判断一下数据库是否存在,如果不存在再创建2、如果数据库名是关键字和特殊字符要报错。解决:在特殊字符、关键字行加上反引号3、创建数据库的时候可以指定字符编码脚下留心:创建数据库如果不指定字符编码,默认和MySQL服务器的字符编码是一致的。1.5.2 显示所有数据库语法:show databases例题mysql> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | mysql | | performance_schema | | test | +--------------------+ 4 rows in set (0.00 sec)注意:数据库安装后,只带上面四个数据库1.5.3 删除数据库语法:drop database [if exists] 数据库名例题mysql> drop database `create`; Query OK, 0 rows affected (0.00 sec) mysql> drop database `%$`; Query OK, 0 rows affected (0.00 sec) -- 判断数据库是否存在,如果存在就删除 mysql> drop database if exists stu; Query OK, 0 rows affected (0.00 sec)小结:1、如果删除的数据库不存在,会报错解决:删除之前判断一下,如果存在就删除1.5.4 显示创建数据库的语句语法:show create database 数据库名例题:mysql> show create database emp; +----------+-------------------------------------------------------------+ | Database | Create Database | +----------+-------------------------------------------------------------+ | emp | CREATE DATABASE `emp` /*!40100 DEFAULT CHARACTER SET gbk */ | +----------+-------------------------------------------------------------+ 1 row in set (0.00 sec)1.5.5 修改数据库只能修改数据库选项,数据库的选项只有字符编码语法:alter database 数据库名 charset=字符编码例题:mysql> alter database emp charset=utf8; Query OK, 1 row affected (0.00 sec)小结:1、修改数据库只能修改数据库的字符编码2、在MySQL中utf字符编码之间没有横杆 utf81.5.6 选择数据库语法:use 数据库名例题mysql> use emp; Database changed1.6 表的操作mysql> create database data; Query OK, 1 row affected (0.00 sec) mysql> use data; Database changed1.6.1 创建表语法:create table [if not exists] `表名`( `字段名` 数据类型 [null|not null] [default] [auto_increment] [primary key] [comment], `字段名 数据类型 … )[engine=存储引擎] [charset=字符编码] null|not null 是否为空 default: 默认值 auto_increment 自动增长,默认从1开始,每次递增1 primary key 主键,主键的值不能重复,不能为空,每个表必须只能有一个主键 comment: 备注 engine 引擎决定了数据的存储和查找 myisam、innodb 脚下留心:表名和字段名如果用了关键字,要用反引号引起来。例题: -- 设置客户端和服务器通讯的编码 mysql> set names gbk; Query OK, 0 rows affected (0.00 sec) -- 创建简单的表 mysql> create table stu1( -> id int auto_increment primary key, -> name varchar(20) not null -> )engine=innodb charset=gbk; Query OK, 0 rows affected (0.11 sec) -- 创建复杂的表 mysql> create table stu2( -> id int auto_increment primary key comment '主键', -> name varchar(20) not null comment '姓名', -> `add` varchar(50) not null default '地址不详' comment '地址', -> score int comment '成绩,可以为空' -> )engine=myisam; Query OK, 0 rows affected (0.06 sec)小结:1、如果不指定引擎,默认是innodb2、如果不指定字符编码,默认和数据库编码一致3、varchar(20) 表示长度是20个字符数据表的文件一个数据库对应一个文件夹 一个表对应一个或多个文件 引擎是myisam,一个表对应三个文件 .frm :存储的是表结构 .myd :存储的是表数据 .myi :存储的表数据的索引 引擎是innodb,一个表对应一个表结构文件,innodb的都有表的数据都保存在ibdata1文件中,如果数据量很大,会自动的创建ibdata2,ibdata3...innodb和myisam的区别引擎 myisam1、查询速度快2、容易产生碎片3、不能约束数据innodb1、以前没有myisam查询速度快,现在已经提速了2、不产生碎片3、可以约束数据脚下留心:推荐使用innodb。1.6.2 显示所有表语法show tables;例题:mysql> show tables; Empty set (0.00 sec)1.6.3 显示创建表的语句语法show create table; -- 结果横着排列 show create table \G -- 将结果竖着排列例题1.6.4 查看表结构语法desc[ribe] 表名例题-- 方法一 mysql> describe stu2; +-------+-------------+------+-----+----------+----------------+ | Field | Type | Null | Key | Default | Extra | +-------+-------------+------+-----+----------+----------------+ | id | int(11) | NO | PRI | NULL | auto_increment | | name | varchar(20) | NO | | NULL | | | add | varchar(50) | NO | | 地址不详 | | | score | int(11) | YES | | NULL | | +-------+-------------+------+-----+----------+----------------+ 4 rows in set (0.05 sec) -- 方法二 mysql> desc stu2; +-------+-------------+------+-----+----------+----------------+ | Field | Type | Null | Key | Default | Extra | +-------+-------------+------+-----+----------+----------------+ | id | int(11) | NO | PRI | NULL | auto_increment | | name | varchar(20) | NO | | NULL | | | add | varchar(50) | NO | | 地址不详 | | | score | int(11) | YES | | NULL | | +-------+-------------+------+-----+----------+----------------+ 4 rows in set (0.00 sec)1.6.5 复制表语法一:create table 新表 select 字段 from 旧表特点:不能复制父表的键,能够复制父表的数据语法二:create table 新表 like 旧表特点:只能复制表结构,不能复制表数据小结:*表示所有字段1.6.6 删除表语法:drop table [if exists] 表1,表2,… 例题:-- 删除表 mysql> drop table stu4; Query OK, 0 rows affected (0.06 sec) -- 如果表存在就删除 mysql> drop table if exists stu4; Query OK, 0 rows affected, 1 warning (0.00 sec) -- 一次删除多个表 mysql> drop table stu2,stu3; Query OK, 0 rows affected (0.03 sec)1.6.7 修改表语法:alter table 表名 创建初始表mysql> create table stu( -> id int, -> name varchar(20) -> ); Query OK, 0 rows affected (0.00 sec)1、添加字段:alter table 表名add [column] 字段名 数据类型 [位置]mysql> alter table stu add `add` varchar(20); -- 默认添加字段放在最后 Query OK, 0 rows affected (0.05 sec) mysql> alter table stu add sex char(1) after name; -- 在name之后添加sex字段 Query OK, 0 rows affected (0.00 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> alter table stu add age int first; -- age放在最前面 Query OK, 0 rows affected (0.00 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> desc stu; +-------+-------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+-------------+------+-----+---------+-------+ | age | int(11) | YES | | NULL | | | id | int(11) | YES | | NULL | | | name | varchar(20) | YES | | NULL | | | sex | char(1) | YES | | NULL | | | add | varchar(20) | YES | | NULL | | +-------+-------------+------+-----+---------+-------+ 5 rows in set (0.00 sec)2、删除字段:alter table 表 drop [column] 字段名mysql> alter table stu drop age; -- 删除age字段 Query OK, 0 rows affected (0.00 sec) Records: 0 Duplicates: 0 Warnings: 03、修改字段(改名):alter table 表 change [column] 原字段名 新字段名 数据类型 …-- 将name字段更改为stuname varchar(10) mysql> alter table stu change name stuname varchar(10); Query OK, 0 rows affected (0.02 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> desc stu; +---------+-------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +---------+-------------+------+-----+---------+-------+ | id | int(11) | YES | | NULL | | | stuname | varchar(10) | YES | | NULL | | | sex | char(1) | YES | | NULL | | | add | varchar(20) | YES | | NULL | | +---------+-------------+------+-----+---------+-------+ 4 rows in set (0.00 sec)4、修改字段(不改名):alter table 表 modify 字段名 字段属性…-- 将sex数据类型更改为varchar(20) mysql> alter table stu modify sex varchar(20); Query OK, 0 rows affected (0.00 sec) Records: 0 Duplicates: 0 Warnings: 0 -- 将add字段更改为varchar(20) 默认值是‘地址不详’ mysql> alter table stu modify `add` varchar(20) default '地址不详'; Query OK, 0 rows affected (0.00 sec) Records: 0 Duplicates: 0 Warnings: 05、修改引擎:alter table 表名 engine=引擎名mysql> alter table stu engine=myisam; Query OK, 0 rows affected (0.01 sec) Records: 0 Duplicates: 0 Warnings: 06、修改表名:alter table 表名 rename to 新表名-- 将stu表名改成student mysql> alter table stu rename to student; Query OK, 0 rows affected (0.00 sec)7、将表移动到其他数据库-- 将当前数据库中的student表移动到php74数据库中改名为stu mysql> alter table student rename to php74.stu; Query OK, 0 rows affected (0.00 sec)1.7 数据操作1.7.1 插入数据语法:insert into 表名 (字段名, 字段名,…) values (值1, 值1,…)1、插入所有字段-- 插入所有字段 mysql> insert into stu (id,stuname,sex,`add`) values (1,'tom','男','北京'); Query OK, 1 row affected (0.00 sec) -- 插入部分字段 mysql> insert into stu(id,stuname) values (2,'berry'); -- 插入的字段和表的字段可以顺序不一致。但是插入字段名和插入的值一定要一一对应 mysql> insert into stu(sex,`add`,id,stuname) values ('女','上海',3,'ketty'); Query OK, 1 row affected (0.00 sec) -- 插入字段名可以省略 mysql> insert into stu values(4,'rose','女','重庆'); Query OK, 1 row affected (0.00 sec)小结:1、插入字段名的顺序和数据表中字段名的顺序可以不一致 2、插入值的个数、顺序必须和插入字段名的个数、顺序要一致。 3、如果插入的值的顺序和个数与表字段的顺序个数一致,插入字段可以省略。2、插入默认值和空值mysql> insert into stu values (5,'jake',null,default); Query OK, 1 row affected (0.05 sec)小结:default关键字用来插入默认值,null用来插入空值.3、插入多条数据mysql> insert into stu values (6,'李白','男','四川'),(7,'杜甫','男','湖北'); Query OK, 2 rows affected (0.00 sec) Records: 2 Duplicates: 0 Warnings: 01.7.2 更新数据语法:update 表名 set 字段=值 [where 条件]-- 将berry性别改为女 mysql> update stu set sex='女' where stuname='berry'; Query OK, 1 row affected (0.06 sec) -- 将编号是1号的学生性别改成女,地址改为上海。 mysql> update stu set sex='女',`add`='上海' where id=1; Query OK, 1 row affected (0.00 sec)1.7.3 删除数据语法:delete from 表名 [where 条件]-- 删除1号学生 mysql> delete from stu where id=1; -- 删除名字是berry的学生 mysql> delete from stu where stuname='berry'; Query OK, 1 row affected (0.00 sec) -- 删除所有数据 mysql> delete from stu; Query OK, 5 rows affected (0.00 sec)多学一招:delete from 表和truncate table 表区别?1、delete from 表:遍历表记录,一条一条的删除 2、truncate table:将原表销毁,再创建一个同结构的新表。就清空表而言,这种方法效率高。1.7.4 查询数据语法:select 列名 from 表名例题-- 查询id字段的值 mysql> select id from stu; -- 查询id,stuname字段的值 mysql> select id,stuname from stu;、 -- 查询所有字段的值 mysql> select * from stu;1.7.5 数据传输时使用字符集发现:在插入数据的时候,如果有中文会报错(或者中文无法插入)分析:1、查看客户端发送的编码2、查看服务器接受,返回的编码更改接受客户端指令的编码mysql> set character_set_client=gbk; Query OK, 0 rows affected (0.05 sec)原因:返回编码是utf8,客户端是gbk;测试:成功可以通过set names一次性设置小结:1、设置什么编码取决于客户端的编码2、通过set names 设置编码1.8 补充知识每次执行指令要进入相应的目录中,麻烦,可以通过环境变量简化操作。1.8.1 环境变量配置我的电脑右键——属性——高级将mysql指令目录地址添加到环境变量的Path值中这时候就可以在任意目录下使用mysql指令原理:1、输入指令后,首先在当前目录下查找,如果当前目录下找不到,就到环境变量的Path中查找2、Path中有很多目录,从前往后查找1.8.2 校对集1、概念:在某种字符集下,字符之间的比较关系,比如a和B的大小关系,如果区分大小写a>B,如果不区分大小写则a<B。比如赵钱孙李大小关系,不同的标准关系不一样2、校对集依赖与字符集,不同的字符集的的比较规则不一样,如果字符集更改,校对集也重新定义。3、不同的校对集对同一字符序列比较的结果是不一致的。4、 可以在定义字符集的同时定义校对集、 语法: collate = 校对集例题:定义两个表,相同字符集不同校对集mysql> create table stu1( -> name char(1) -> )charset=utf8 collate=utf8_general_ci; Query OK, 0 rows affected (0.05 sec) mysql> create table stu2( -> name char(1) -> )charset=utf8 collate=utf8_bin; Query OK, 0 rows affected (0.05 sec) mysql> insert into stu1 values ('a'),('B'); Query OK, 2 rows affected (0.00 sec) Records: 2 Duplicates: 0 Warnings: 0 mysql> insert into stu2 values ('a'),('B'); Query OK, 2 rows affected (0.00 sec) Records: 2 Duplicates: 0 Warnings: 0测试:两个表的数据都是有小到大排序mysql> select * from stu1 order by name; -- 不区分大小写 +------+ | name | +------+ | a | | B | +------+ 2 rows in set (0.08 sec) mysql> select * from stu2 order by name; -- 区分大小写 +------+ | name | +------+ | B | | a | +------+ 2 rows in set (0.00 sec) 小结校对集规则:_bin:按二进制编码比较,区别大小写_ci:不区分大小写