



第一章 前言
我们现实生活中的协议是指相互遵守的规定,单方面违背,协议不成立;而在互联网交互的过程中,也存在这许多协议,例如FTP、HTTP、STMP、TCP/IP等。
而HTTP协议则是web服务器和web客户端达成的一种可靠的数据传输协议,通过HTTP可以从遍布全世界的Web服务器上将JPEG图片,HTML页面,文本文件,MPEG电影,WAV音频文件和其他资源信息块迅速、便捷、可靠地搬移到人们桌面上的Web浏览器上去。它能够确保数据在传输的过程当中不会损坏或者产生混乱。这样,对用户来说是个好事,同样对internet应用的开发人员来说也是一件好事。因为我们在开发过程中也不需要担心自己的页面和数据会在传输过程中发生破坏和畸变了。
第二章 WEB客户端和服务器
Web内容都是存储在Web服务器上的。Web服务器所使用的是HTTP协议,因此经常会被称为HTTP服务器。这些HTTP服务器存储了因特网中的数据,如果HTTP客户端发出请求的话,它们会提供数据。客户端向服务器发送HTTP请求,服务器会在HTTP响应中回送所请求的数据。
那么一次请求和响应的过程中发生了什么?

HTTP属于无状态链接协议,即是限制每次连接只处理一个请求。服务器处理完客户的请求,并收到客户的应答后,即断开连接。采用这种方式可以节省传输时间和服务器资源。
当然也有有状态链接,那就是我们常用的QQ。H5新增的特性中也包含Websocket帮助我们构建长链接。
第三章 资源和媒体类型
web服务器是web资源的宿主,而web资源就是我们常见的web内容的源头,最简单的web资源就是我们服务器中的静态文件:文本文件,HTML文档,JPEG图片文件,mp4文件等等。
当然web资源也可以是动态生成的,类似搜索引擎生成的页面,qq空间的动态等,总之,所有类型的内容来源都是资源。
因特网上有数千种不同类型的数据类型,HTTP在传输的过程中为每个传输的数据都打上了名为MIME类型的数据类型标签,描述并标记多媒体内容。

web浏览器请求一个网站的时候往往会发布多个HTTP请求,比如我们在浏览一个具有丰富图片的的web页面的时候,浏览器会执行一次HTTP请求来获取描述页面布局的HTML,然后发布另外的请求来获取每个嵌入式的图片,这些图片甚至可能位于不同的服务器上。因此,一个web页面通常不是单个资源,而是一组资源的集合。
web服务器会为所有的HTTP对象数据附加一个MIME类型,当浏览器从服务器中取回一个对象的时候,会查看相关的MIME类型。看看它是否知道应该如何处理这个对象。对象的类型写在响应的content-type头中;同样,请求的时候浏览器也会告知服务器请求数据类型。
常见的MIME类型:
- HTML 格式的文本文档由 text/html 类型来标记。
- 普通的 ASCII 文本文档由 text/plain 类型来标记。
- JPEG 格式的图片为 image/jpeg 类型。
- GIF 格式的图片为 image/gif 类型。
以application开头的媒体格式类型:
- application/xhtml+xml :XHTML格式
- application/xml : XML数据格式
- application/atom+xml :Atom XML聚合格式
- application/json : JSON数据格式
- application/octet-stream : 二进制流数据(如常见的文件下载)
- application/x-www-form-urlencoded :
<form encType=''>中默认的encType,form表单数据被编码为key/value格式发送到服务器(表单默认的提交数据的格式) - multipart/form-data : 需要在表单中进行文件上传使用的数据格式。
当然还有很多类型,我们就不一一列举了。
MIME 参考手册:
第四章 URL
统一资源定位符(Uniform Resource Locator)是资源标识符最常见的形式。URL描述了一台特定服务器上某资源的特定位置。它们可以明确说明如何从一个精确、固定的位置获取资源。互联网上的每个文件都有一个唯一的URL,它包含的信息指出文件的位置以及浏览器应该怎么处理它。
大部分 URL 都遵循一种标准格式, 这种格式包含三个部分。
- URL 的第一部分被称为方案(scheme), 说明了访问资源所使用的协议类型。 这部
分通常就是 HTTP 协议(http://)。 - 第二部分给出了服务器的因特网地址(比如,http://www.itheima.com)。
- 其余部分指定了 Web 服务器上的某个资源(比如, /static/image/common/zixuelogo.png)。
URL可以更为细致的进行划分。
foo://username:password@xxx.xx.xx:8080/over/there/index.html?type=answer&name=yanshiba#nose
\_/ \_______________/ \_________/ \__/ \___/ \_/ \______________________/ \__/
| | | | | | | |
| userinfo host port | | query fragment
| \________________________________/\_____________|____|/ \__/ \__/
scheme | | | | | |
name authority | | | | |
path | | interpretable as keys
| |
\_______________________________________________|____|/ \____/ \_____/
| | | | |
hierarchical part | | interpretable as values
| |
interpretable as filename |
|
|
interpretable as extension第五章 方法
HTTP支持几种不同请求和命令,这些命令被称为HTTP方法,每条HTTP请求报文都包含一个方法。 这个方法会告诉服务器要执行什么动作(获取一个Web页面、发送一段信息、删除一个文件等);
我们在学习form表单的时候也知道method可以写作post和get。这就是HTTP请求的方法。
请求方法如下:
| 请求方法 | 描述 |
|---|---|
| GET | 获取一个URL指定的资源,即资源实体 |
| POST | 向服务器提交数据 |
| PUT | 向服务器提交数据 |
| DELETE | 请求源服务器删除Request-URI标志的资源 |
| HEAD | 获取一个指定资源的头信息 |
| OPTIONS | 获取服务器支持的方法 |
我们随后学习的node和ajax中都会用到HTTP请求具体的方法实现。
第六章 状态码
每条HTTP响应报文返回时都会携带一个状态码。状态码是一个三位数字的代码,告知客户端请求是否成功, 或者是否需要采取其他动作。
状态码分成如下几个系列:
| 状态码 | 定义 | 说明 |
|---|---|---|
| 1XX | 请求被接受 | 一般只在实验环境下使用 |
| 2XX | 成功 | 操作成功的收到,理解和接收 |
| 3XX | 重定向 | 为了完成请求,进行进一步措施 |
| 4XX | 客户端错误 | 请求的语法有错误或者不能完全被满足 |
| 5XX | 服务器错误 | 服务器无法完成明显有效的请求 |
常见的HTTP状态码:
| HTTP状态码 | 描述 |
|---|---|
| 200 | OK。文档正确返回 |
| 301/2 | 永久/临时重定向 |
| 304 | not modified 未修改(原有的缓存可以继续使用) |
| 404 | 请求的网页不存在 |
| 503 | 服务器暂时不可用 |
| 500 | 服务器内部错误 |
第七章 报文
HTTP报文是由一行一行的简单字符串组成的。HTTP报文都是纯文本,不是二进制代码,所以人们可以很方便地对其进行读写。
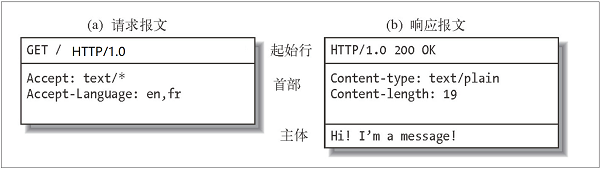
从Web客户端发往Web服务器的HTTP报文称为请求报文(request message)。从服务器发往客户端的报文称为响应报文(response message)。
HTTP 报文包括以下三个部分:
起始行
报文的第一行就是起始行, 在请求报文中用来说明要做些什么, 在响应报文中说明
出现了什么情况。- 请求行部分由 请求方法(GET,POST等),请求路径,协议版本组成。
- 响应行部分由 协议版本,状态码,状态文字组成。
- 首部字段
起始行后面有零个或多个首部字段。 每个首部字段都包含一个名字和一个值, 为了
便于解析, 两者之间用冒号来分隔。 首部以一个空行结束。 - 主体
空行之后就是可选的报文主体了, 其中包含了所有类型的数据。 请求主体中包括了
要发送给 Web 服务器的数据; 响应主体中装载了要返回给客户端的数据。 起始行
和首部都是文本形式且都是结构化的, 而主体则不同, 主体中可以包含任意的二进
制数据(比如图片、视频、音轨、软件程序)。 当然, 主体中也可以包含文本。
HTTP报文常见的内容:http://www.cnblogs.com/Joans/p/3956490.html\
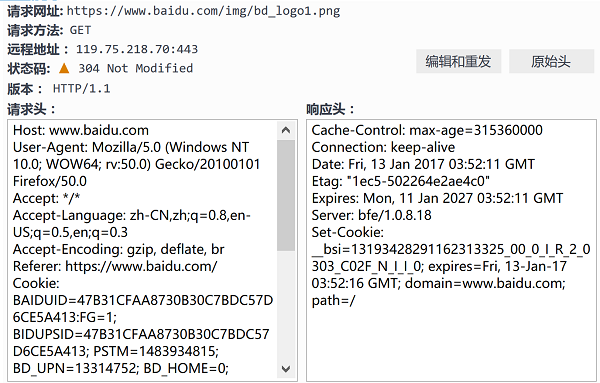
使用火狐浏览器打开一个网页,找到其中一个网络请求查看报文:
评论 (0)